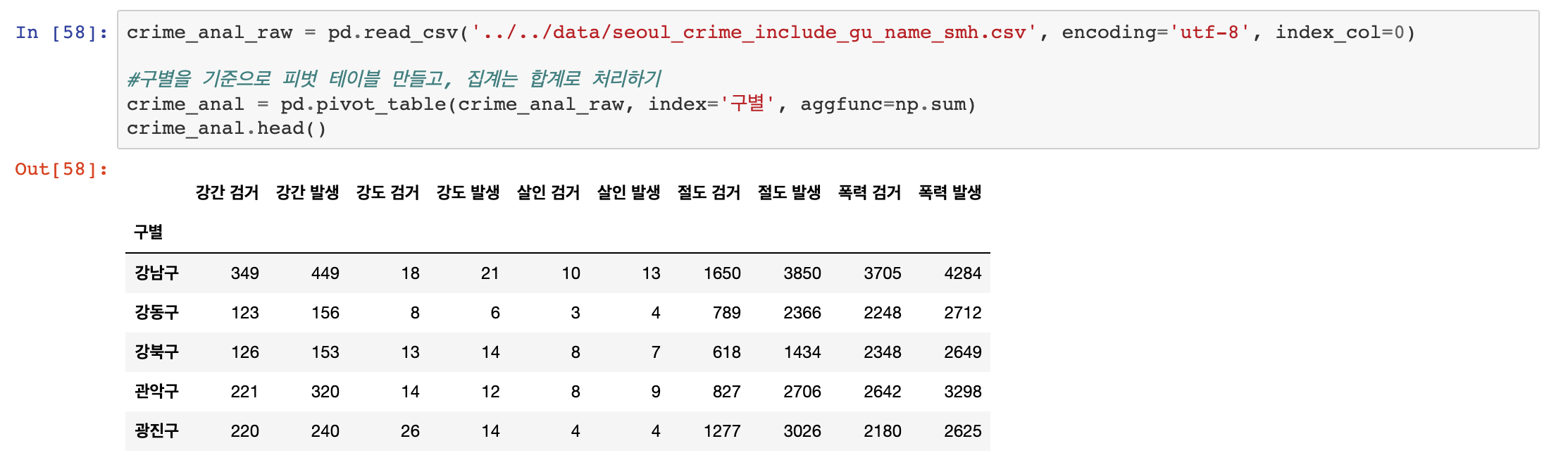
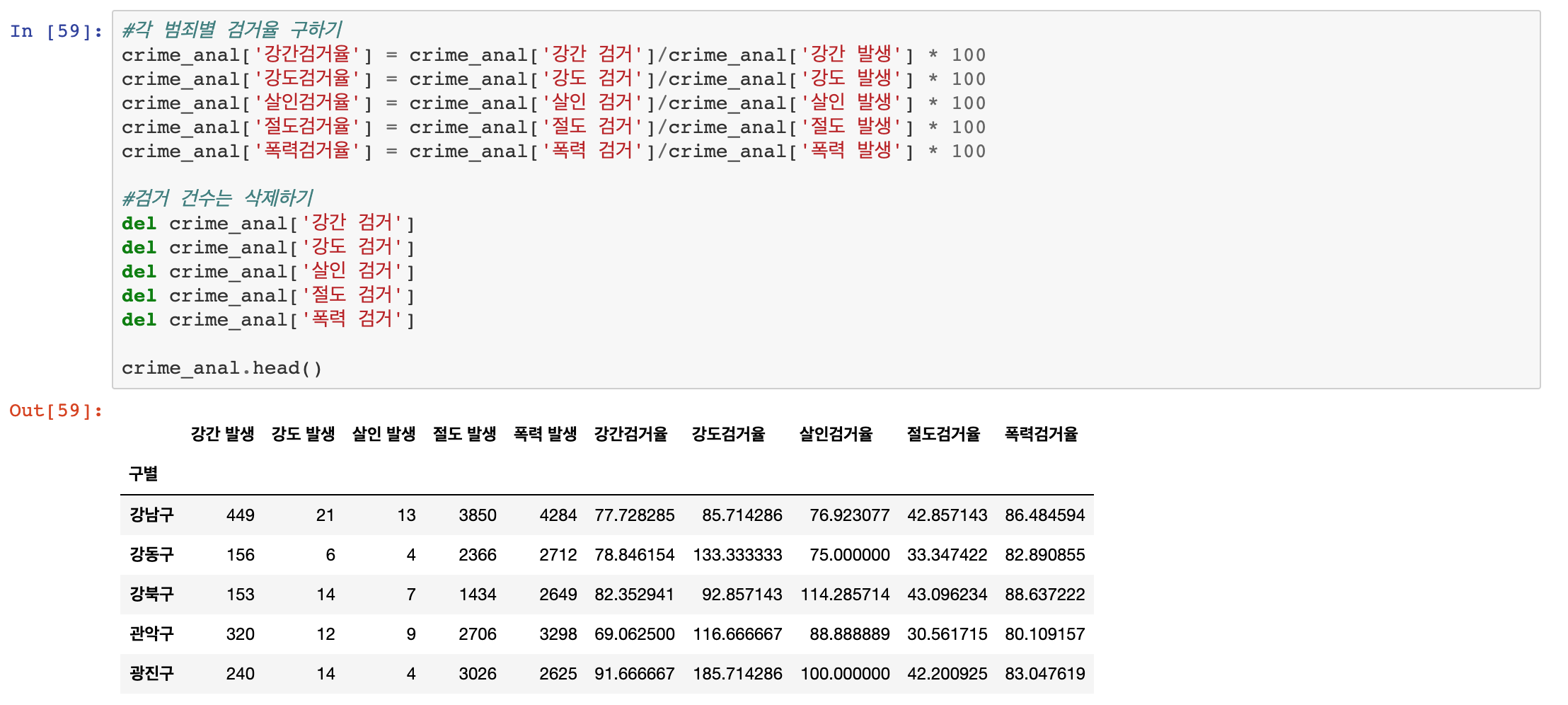
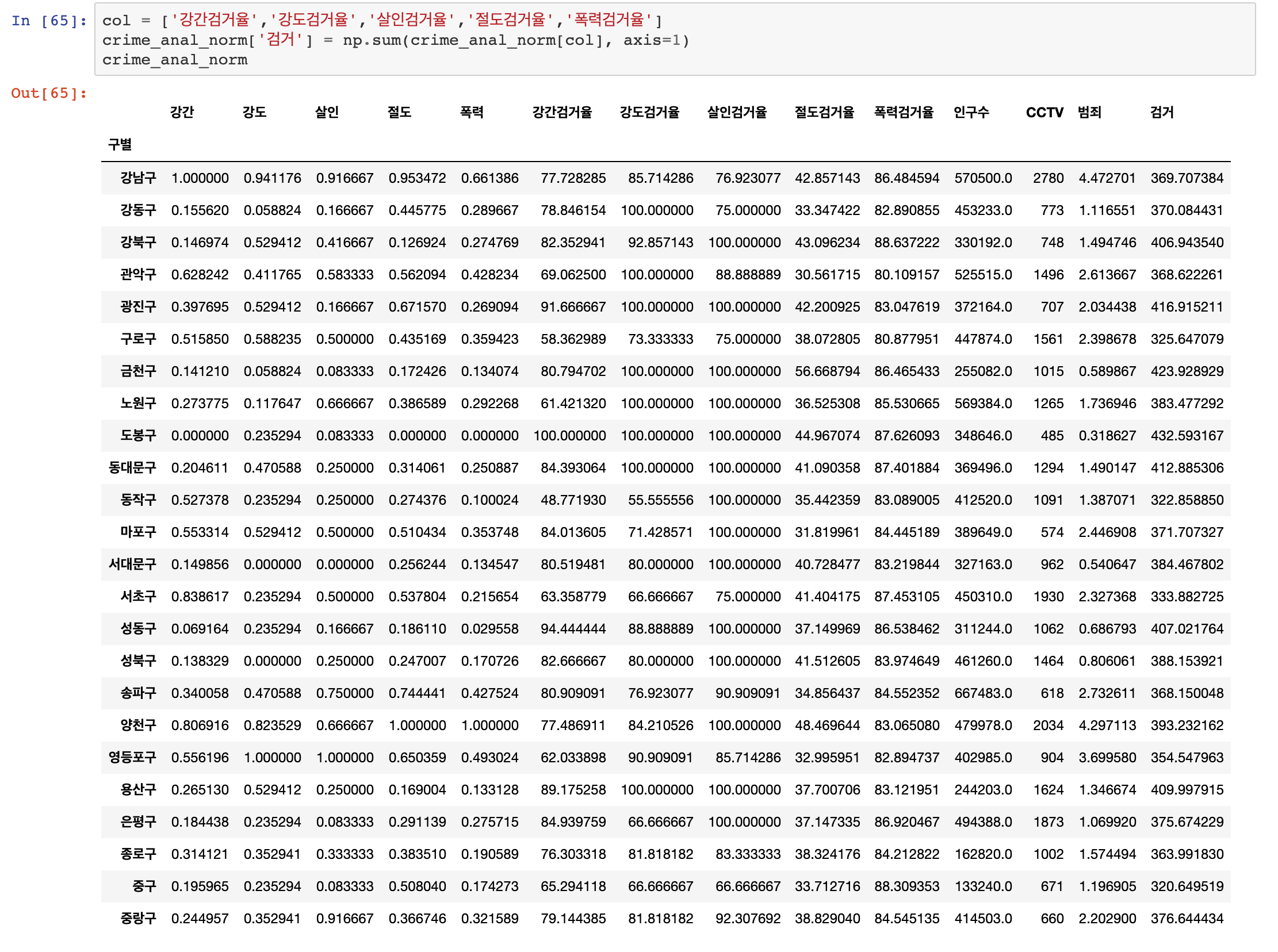
이번 포스팅에서는 범죄 데이터 분석을 Seaborn을 이용하여 시각화로 나타내 보도록 하겠습니다.
우선, 한글이 깨지는것을 방지하기 위해 폰트 이슈부터 해결하겠습니다.
이어서 바로 그래프도 보겠습니다.


상관관계를 아주 손쉽게 시각화해서 보여주고 있습니다.
잠시 분석을 해보면
- 강도 - 폭력
- 살인 - 폭력
- 강도 - 살인
전부다 양의 상관 관계를 갖는다는 것이 확인됩니다.
즉 예를 들어 강도를 기준으로 한다면 폭력과 살인이 많이 일어난다는 이야기가 됩니다.
다음은 CCTV와 살인, 강도에 대한 그래프를 확인해보겠습니다.

위의 시각화 데이터를 보면 분명히 인구수가 증가할수록 범죄가 증가하는 것이 확인됩니다.
특히 살인은 매우 많이 일어나는 것이 확인되네요
또한 CCTV와 살인은 상관관계가 낮아 보입니다.( 그래프의 기울기 확인 )
하지만 CCTV가 없을 때 살인사건이 많이 일어나는 것이 확인됩니다.
다음은 인구수와 살인 및 폭력 검거율을 확인해보겠습니다.

이번 분석은 음의 상관관계를 의미합니다. 인구수가 많아질수록 폭력 검거율은 줄어들고, CCTV가 많아질수록 검거율도 낮아지네요??
다음은 heatmap을 이용해서 전체 검거율을 확인해보겠습니다.
이때 검거 항목 최고값을 100으로 한정 해 놓고 계산하겠습니다.
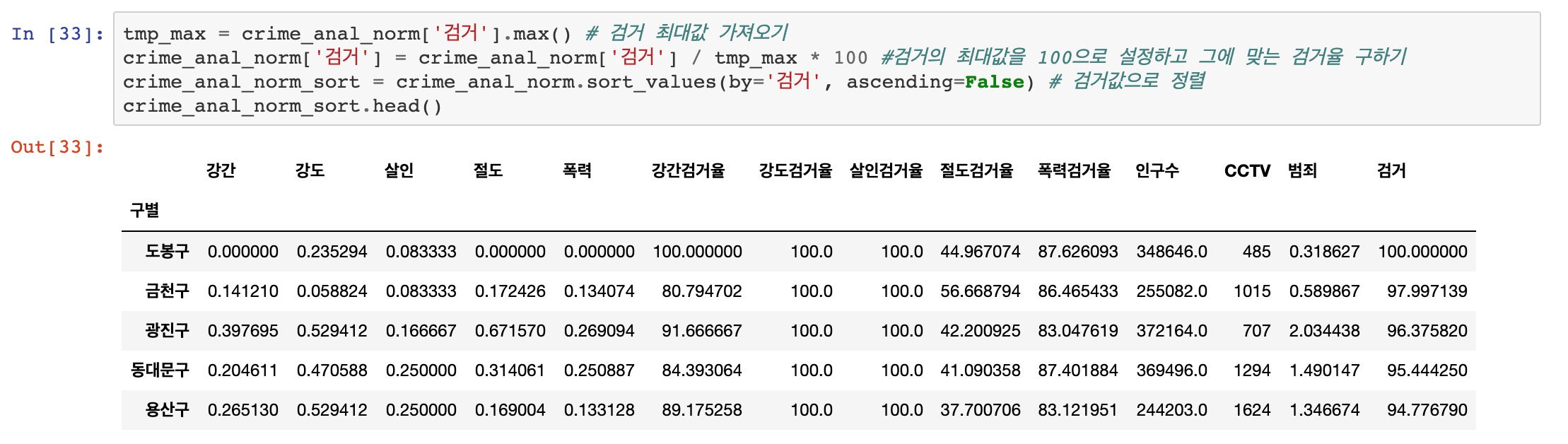


결과를 보니 절도 검거율은 다른 검거율에 비해서 매우 낮다고 볼 수 있겠습니다.
그래프의 하단으로 갈수록 검거율이 낮아지는데, 강남 3구 중 하나인 서초구가 보입니다.
검거율이 우수한 지역은 도봉구, 광진구, 성동구가 있네요.
이어서 정규화된 발생 건수로 확인해 보겠습니다.

발생 건수로는 강남구, 양천구, 영등포구가 범죄 발생 건수가 높게 나타납니다. (그리고 송파구와 서초구도 높네요)
이번 포스팅에서는 앞서 정리한 데이터를 Seaborn을 사용하여 시각화로 나타내 보았습니다. 시각화 분석이 조금 더 한눈에 들어오는 것 같죠? Seaborn을 활용하면 더욱 다양하고 예쁘게 시각화를 할 수 있습니다.
'Programming > 통계 데이터 분석' 카테고리의 다른 글
| [Python] pivot 테이블을 활용한 범죄 데이터 (pivot_예제) (0) | 2021.04.04 |
|---|---|
| [Python] pivot_table을 활용해 원하는 기준 만들기 (0) | 2021.04.02 |
| [Python] CCTV 현황 그래프로 분석하기 (0) | 2021.04.01 |
| [Python]CCTV 데이터와 인구 현황 데이터를 합치고 분석하기 (0) | 2021.02.18 |
| [Python] 서울시 CCTV data와 인구현황 data 파악하기 (0) | 2021.02.15 |