이번 포스팅에서는 앞서 분석한 CCTV 현황을 그래프로 분석을 해도 록 하겠습니다.
드디어 CCTV현황을 그래프로!
드디어 matplotlib를 이용해 데이터를 시각화해 줄 수 있지만, 아직 한글 처리 문제가 남아있습니다. 기본적으로 matplot은 한글 폰트를 지원하지 않기 때문에 matplotlib의 폰트부터 변경시켜 보겠습니다. 순서는 다음과 같습니다.
- platform 모듈 임포트 하기
- OS를 구분 해 줄 수 있습니다.
- matplotlib 모듈 임포트 하기
- 시각화를 하기 위함이겠죠?
- OS를 구분하여 폰트를 각각 설정해 줍니다.

폰트 설정이 끝났으면 다시 한번 결과를 확인해보겠습니다.

pandas 데이터에 바로 plot 명령을 이용해 데이터를 바로 그려 볼 수 있습니다.

예쁘고 쉬운 보기를 위해서 정렬을 해보도록 하겠습니다!

이제! 시각화가 되었으니 다시 한번 분석을 해보도록 하겠습니다. 이번엔 비율입니다!
먼저 시각화가 되어있는 그래프를 보면 CCTV 개수 자체는 강남구가 월등하게 많은 것을 할 수 있습니다.. 또한 가장 CCTV가 많이 없는 그룹도 알 수 있죠? 이어서 인구 대비 CCTV 비율을 계산해보도록 하겠습니다. 간단하게 소계 / 인구 * 100을 하면 될 것 같습니다.
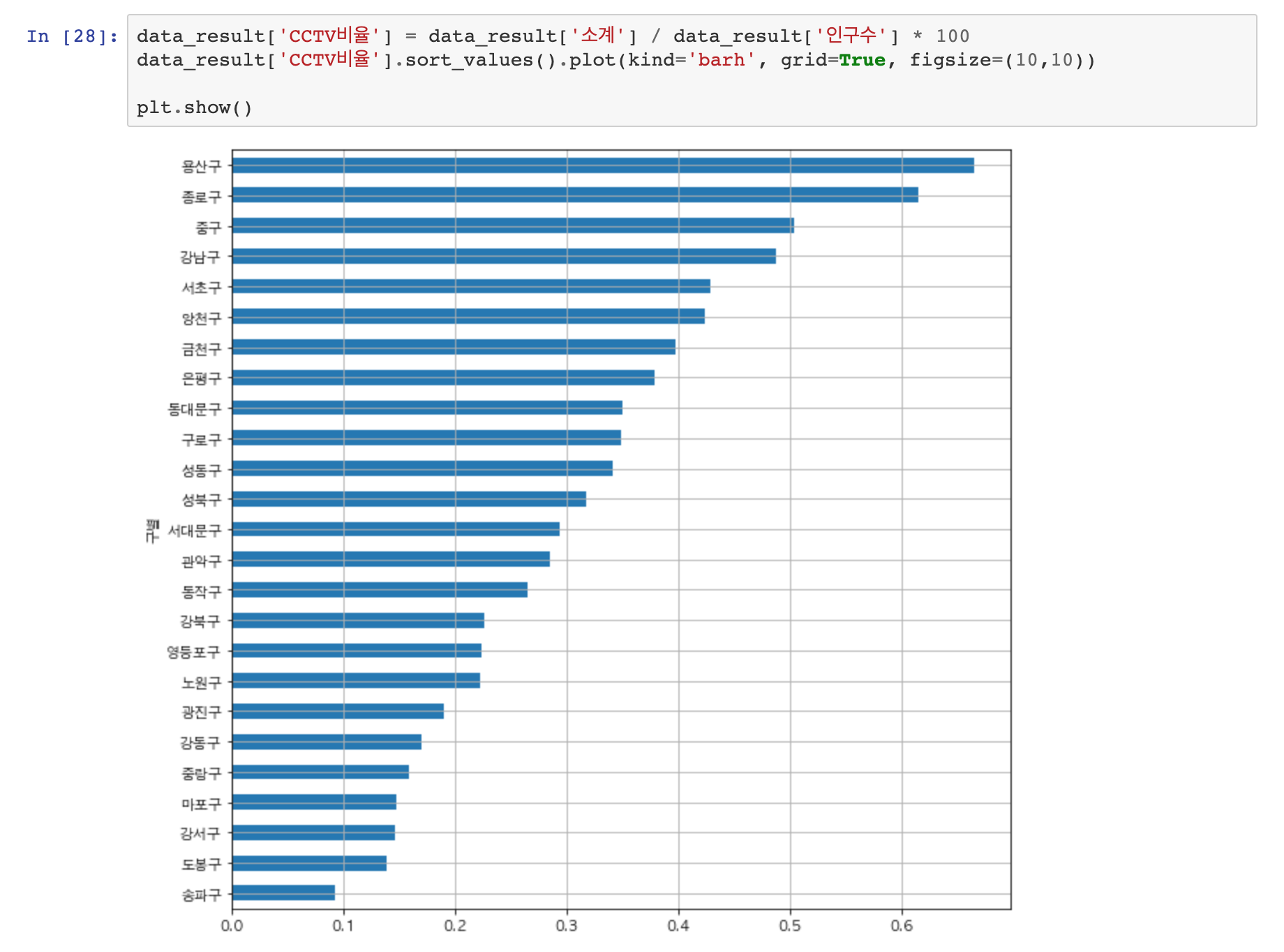
인구수 대비 CCTV 수는 용산구와 종로구가 제일 많은 것을 알 수 있습니다. 송파구는 여전히 인구수로 비교하나, 소계로 비교하나 최하위권을 차지하고 있는 것을 확일 할 수 있습니다.
어느 정도 분석은 된 것 같지만 조금 더 자세히 시각화를 해보도록 하겠습니다. scatter를 활용해 보도록 합시다!

표시한 데이터를 대표할 수 있는 직선을 하나 그려보도록 하겠습니다.
직선의 용도는 인구수가 많아질수록 CCTV의 설치량은 많이 지는 것을 한눈에 알아볼 수 있게 해 줍니다. ( 방금 전의 비율과는 무관합니다~!)
그리고 지금 그려보는 직선은 인구별 CCTV에 대한 기준이 된다고 보시면 됩니다.


이제 이 그래프의 직선은 구별 CCTV의 기준값이 됩니다. 이때, 우리가 기준으로 삼을 수 있는 조선은 이 직선에 가장 근접한 점을 찾아보면 됩니다.
확인을 해보니 대략 300,000만 명의 인구수일 때, 1,100개의 CCTV가 기준이 된다!라고 볼 수 있습니다.
그렇다면 이 직선을 기준으로 해서 멀리 떨어져 있다는 것은 비정상적으로 많다/ 적다 라는 것입니다.
- 직선보다 위에 있을수록 CCTV가 인구수에 비해 과하게 설치가 되었다
- 직선보다 아래 있을수록 CCTV가 인구수에 비해 부족하다
직선과 멀리 떨어질수록 생산도 다르게 표현해주고, 기준점에서 많이 벗어난 구의 이름을 표시해 보도록 하겠습니다.
따라서 직선과의 오차를 구하는 코드를 작성하고, 오차가 큰 순으로 데이처를 정렬해서 그래프를 그려보도록 하겠습니다.
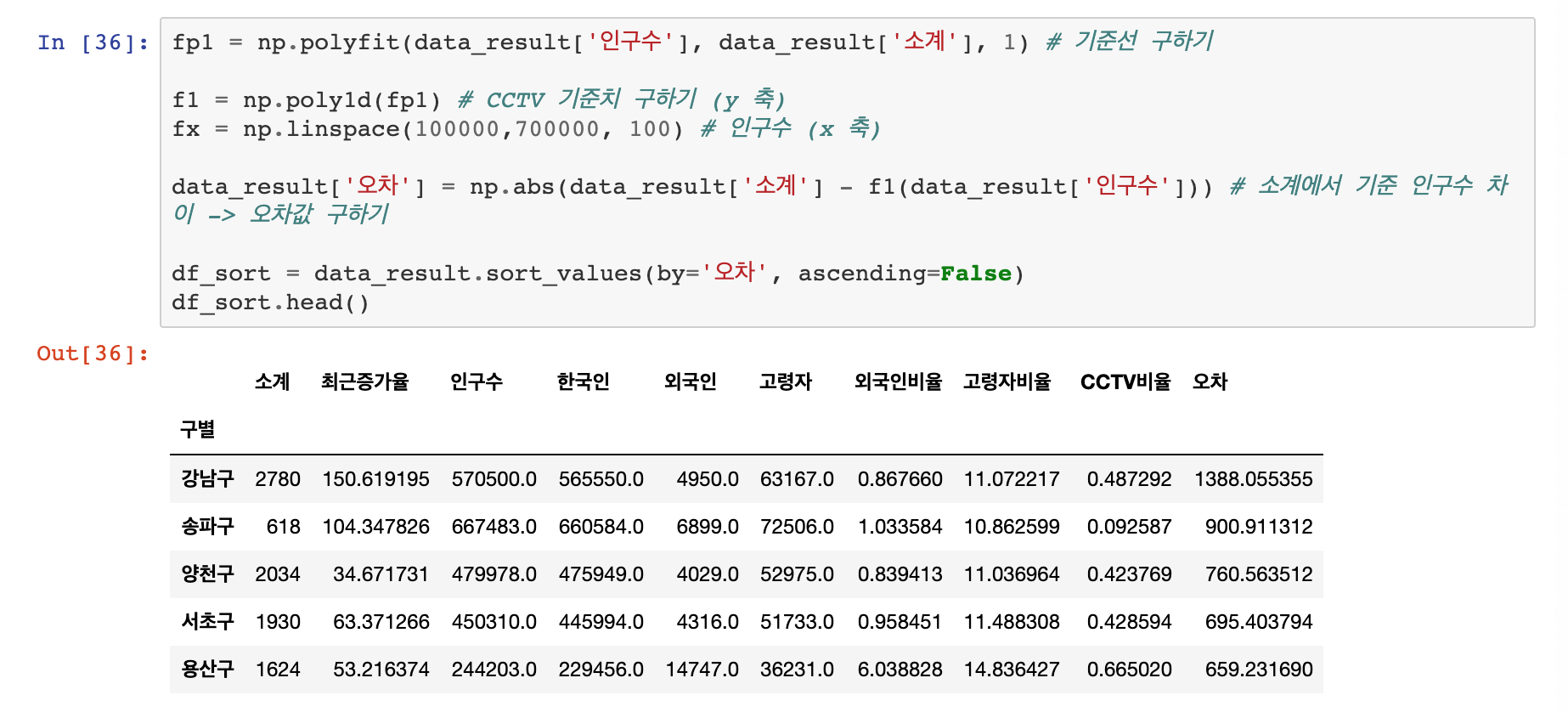


결론
직선을 기준으로, 위에 있는 강남구, 양천구, 서초구, 은평구, 용산구는 서울시 전체의 지역의 일반적인 경향보다 CCTV가 많이 설치되어있습니다.
그리고 송파구, 강서구, 중랑구, 마포구, 도봉구는 일반적인 경향보다 CCTV가 적게 설치된 지역입니다.
특히,
- 강남구는 월등히 많은 CCTV를 보유하고 있다
- 송파구는 매우 적은 CCTV를 보유하고 있다
라고 결론을 내릴 수 있습니다.
어려우셨나요? 사실 scatter그래프를 이용해서 분석 한 내용은 정말 고급스러운(어려운) 내용입니다.
다음 포스팅에서는 pandas의 pivot_table을 활용해 원하는 기준 만들기를 해보도록 하겠습니다.
'Programming > 통계 데이터 분석' 카테고리의 다른 글
| [Python] pivot 테이블을 활용한 범죄 데이터 (pivot_예제) (0) | 2021.04.04 |
|---|---|
| [Python] pivot_table을 활용해 원하는 기준 만들기 (0) | 2021.04.02 |
| [Python]CCTV 데이터와 인구 현황 데이터를 합치고 분석하기 (0) | 2021.02.18 |
| [Python] 서울시 CCTV data와 인구현황 data 파악하기 (0) | 2021.02.15 |
| [Python] Pandas 기본 (통계 데이터 분석) (1) | 2021.02.09 |