지난 포스팅에서 정규화의 중요성을 다뤘다면, 이번에는 연속형 특성과 범주형 특성에 대하여 알아보도록 하겠습니다.
연속형 특성과 범주형 특성이란?
지금까지 우리가 살펴보고, 사용했던 데이터는 2차원 실수형 배열로 각 열이 데이터 포인트를 설명하는 연속형 특성 - continuous feature을 살펴보았습니다.
하지만 우리가 수집하는 모든 데이터들이 연속형 특성을 띄고 있다고는 장담할 수 없습니다. 일반적인 특성의 전형적인 형태는 범주형 특성 - categorical feature입니다. 또는 이산형 특성 - discrete feature라고도 합니다.
이러한 범주형 특성, 이산형 특성들은 보통 숫자 값이 아닙니다. 연속적 특성의 예로 들 수 있는 것은 픽셀 밝기나 붓꽃의 측정값 등을 생각해 볼 수 있고, 범주형 특성은 옷의 브랜드, 색상, 상품 분류 등등이 있습니다. 이러한 특성들은 어떠한 상품을 묘사할 수 있는 특성이긴 하지만, 연속된 값으로 나타낼 수는 없습니다. (어디에 속하는 범주의 의미한다는 이야기)
범주형 특성의 특징은 뭔가 비교를 할 수 없다는 것입니다. 예를 들어 책은 옷보다 크거나 작지 않고, 청바지는 책과 옷 사이에 있지 않죠.
| 특성 종류 | 특성 형태 |
| 연속형 특성 (양적 - Quantitative): 몸무게, 매출액, 주가 등 | 5.11121 |
| 범주형 특성 (질적 - Qualitative): 성별, 지역, 만족도 등 | 남/여, 상/중/하 |
특성 공학을 이용한 데이터 표현의 중요성
데이터가 어떤 형태의 특성으로 구성되어 있는가 보다 (연속형인지, 범주형인지) 데이터를 어떻게 표현하는지가 머신러닝 모델의 성능에 영향을 더 많이 줍니다. 일전에 했었던 데이터 스케일랑 작업 같은 것들을 의미하는데요, 예를 들어 측정치가 센티미터인지, 인치로 측정을 했는지에 따라서 머신러닝 모델이 인식하는 데에 차이가 생기기 시작합니다.
또는 확장된 보스턴 데이터셋처럼 각 특성의 상호작용( 특성 간의 곱 )이나 일반적인 다항식을 추가 특성으로 넣는 것이 도움이 될 때도 있습니다.
이처럼 특성 애플리케이션에 가장 적합한 데이터 표현을 찾는 것을 특성 공학 - feature engineering이라고 합니다. 데이터 분석을 할 때 데이터 과학자와 머신러닝 기술자가 실제 문제를 풀기 위해 당면하는 주요 작업 중 하나입니다.
올바른 데이터 표현은 지도 학습 모델에서 적절한 매개변수를 선택하는 것보다 성능에 더 큰 영향을 미칠 때가 많습니다.
범주형 변수
범주형 변수를 알아보기 위해 예제 데이터셋을 판다스로 불러와서 사용해 보도록 하겠습니다. 1994년 인구조사 데이터베이스에서 추출한 미국 성인의 소득 데이터셋의 일부입니다. adult 데이터셋을 사용해 어떤 근로자의 수입이 50,000 달러를 초과하는지, 이하일지 예측하는 모델을 만드려고 합니다.
import pandas as pd
data = pd.read_csv('./data/adult.csv', encoding='utf-8')
display(data)
위 데이터셋은 소득(income)이 <=50와 > 50K라는 두 클래스를 가진 분류 문제로 생각해 볼 수 있습니다. 정확한 소득을 예측해 볼 수도 있겠지만, 그것은 회귀 문제가 됩니다.
어찌 됐든 이 데이터셋에 있는 age와 hours-per-week는 우리가 다뤄봤었던 연속형 특성입니다. 하지만 workclass, education, gender, occupation은 범주형 특성입니다. 따라서 이런 특성들은 어떤 범위가 아닌 고정된 목록 중 하나를 값으로 가지며, 정량적이 아니고 정성적인 속성입니다.
맨 먼저 이 데이터에 로지스틱 회귀 분류기를 학습하면 지도 학습에서 배운 공식이 그대로 사용될 것입니다.
𝑦̂ =𝑤[0]∗𝑥[0]+𝑤[1]∗𝑥[1]+...+𝑤[𝑝]∗𝑥[𝑝]+𝑏
위 공식에 따라 𝑥[i]는 반드시 숫자여야 합니다. 즉 𝑥[1]은 State-gov나 Self-emp-not-inc 같은 문자열 형태의 데이터가 올 수 없다는 이야기입니다. 따라서 로지스틱 회귀를 사용하려면 위 데이터를 다른 방식으로 표현해야 할 것 같습니다. 이제부터 이 문제들을 해결하기 위한 방법에 대해 이야기해 보겠습니다.
범주형 데이터 문제열 확인하기
데이터셋을 읽고 나서 먼저 어떤 열에 어떤 의미 있는 범주형 데이터가 있는지 확인해 보는 것이 좋습니다. 입력받은 데이터를 다룰 때는 정해진 범주 밖의 값이 있을 수도 있고, 철자나 대소문자가 틀려서 데이터를 전처리 해야 할 수도 있을 것입니다. 예를 들어 사람에 따라 남성을 "male"이나 "man"처럼 다르게 표현할 수 있을 수 있기 때문에 이들을 같은 범주의 데이터로 인식시켜 보아야 합니다.
가장 좋은 방법은 pandas에서 value_counts() 메소드를 이용해 각 Series에 유일한 값이 몇 개씩 있는지를 먼저 출력해 보는 것입니다.
import os
import mglearn
#mglearn에서 adult 데이터셋 불러오기
data = pd.read_csv(
os.path.join(mglearn.datasets.DATA_PATH, 'adult.data'),
header=None, index_col=False,
names=['age','workclass','fnlwgt','education','education-num','marital-status','occupation', 'relationship',
'race','gender','capital-gain', 'capital-loss','hours-per-week', 'native-country', 'income'])
data = data[['age','workclass','education','gender','hours-per-week', 'occupation', 'income']]
print(data.gender.value_counts())다행스럽게도 위 데이터셋에는 정확하게 Male과 Female을 가지고 있어서 원-핫-인코딩으로 나타내기 굉장히 좋은 형태입니다. 실제 애플리케이션에서는 모든 열을 살펴보고 그 값들을 확인해야 합니다.
pandas에서는 get_dummies 함수를 사용해 데이터를 매우 쉽게 인코딩할 수 있습니다. get_dummies 함수는 객체 타입(object 또는 문자열 타입 같은 범주형을 가진 열을 자동으로 반환해 줍니다.
print("원본 특성:\n", list(data.columns), "\n")
data_dummies = pd.get_dummies(data)
print("get_dummies 후의 특성:\n", list(data_dummies.columns))연속형 특성인 age와 hours-per-week는 그대로이지만 범주형 특성은 값마다 새로운 특성으로 확장되었습니다. 즉 새로운 열이 추가되겠네요.
data_dummies.head()data_dummies의 values 속성을 이용해 DataFrame을 NumPy 배열로 바꿀 수 있으며, 이를 이용해 머신러닝 모델을 학습시킵니다. 모델을 학습시키기 전에 이 데이터로부터 우리가 예측해야 할 타깃값인 income으로 시작되는 열을 분리해야 합니다. 출력값이나 출력값으로부터 유도된 변수를 특성 표현에 포함하는 것은 지도학습 모델을 만들 때 특히 저지르기 쉬운 실수입니다.
features = data_dummies.loc[:, 'age':'occupation_ Transport-moving']
# Numpy 배열 추출하기
X = features.values
y = data_dummies['income_ >50K'].values
print('X.shape: {} y.shape: {}'.format(X.shape, y.shape))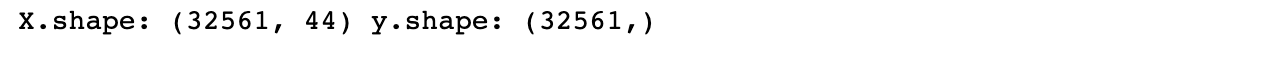
이제 이 데이터는 scikit-learn에서 사용할 수 있는 형태가 되었으므로, 이전과 같은 방식을 사용하여 예측을 해볼 수 있습니다.
from sklearn.linear_model import LogisticRegression
from sklearn.model_selection import train_test_split
X_train, X_test, y_train,y_test = train_test_split(X, y, random_state=0)
logreg = LogisticRegression()
logreg.fit(X_train, y_train)
print("테스트 점수: {:.2f}".format(logreg.score(X_test, y_test)))
숫자로 표현된 범주형 특성
데이터 취합 방식에 따라서 범주형 데이터가 숫자로 취합된 경우도 생깁니다. 범주형 변수가 숫자라고 해서 연속적으로 다뤄도 된다는 의미는 아닙니다. 여러분들이 머신러닝에 사용할 데이터셋을 봤을 때, 순서를 나타낸 숫자가 아닌 단순히 범주를 나타내기 위한 숫자라는 사실을 확인하였으면, 이 값은 이산적이기 때문에 연속형 변수로 다루면 안 된다고 생각해야 합니다.
pandas의 get_dummis 함수는 숫자 특성은 모두 연속형이라고 생각해서 가변수를 만들지 않습니다. 대신 어떤 열이 연속형인지 범주형인지를 지정할 수 있는 scikit-learn의 OneHotEncoder를 사용해 DataFrame에 있는 숫자로 된 열을 문자열로 바꿀 수도 있습니다. 간단한 예를 보겠습니다.
# 숫자 특성과 범주형 문자열 특성을 가진 DataFrame 만들기
demo_df = pd.DataFrame({'숫자 특성' : [0, 1, 2, 1],
'범주형 특성' : ['양말','여우','양말','상자']})
demo_df
단순하게 get_dummies만 사용하면 문자열 특성만 인코딩 되며 숫자 특성은 바뀌지 않습니다.
pd.get_dummies(demo_df)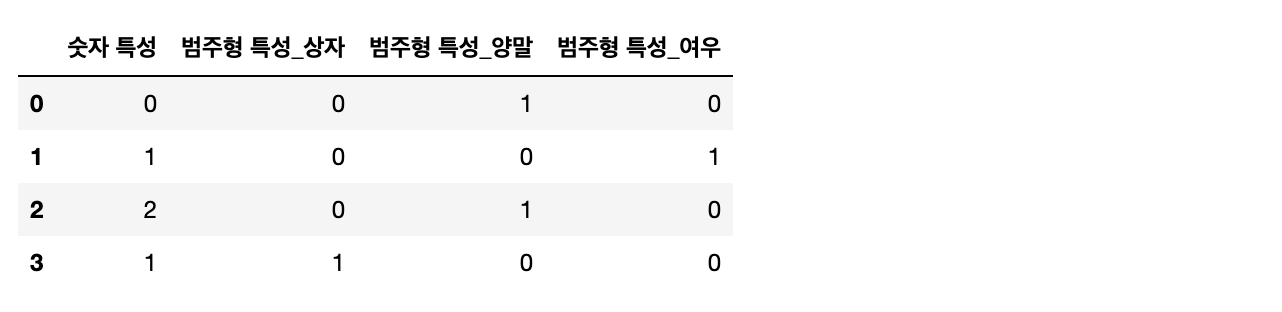
숫자 특성도 가변수로 만들고 싶다면 columns 매개변수에 인코딩 하고 싶은 열을 명시해야 합니다.
# 숫자 특성을 문자열로 변환
demo_df['숫자 특성'] = demo_df['숫자 특성'].astype(str)
pd.get_dummies(demo_df, columns=['숫자 특성', '범주형 특성'])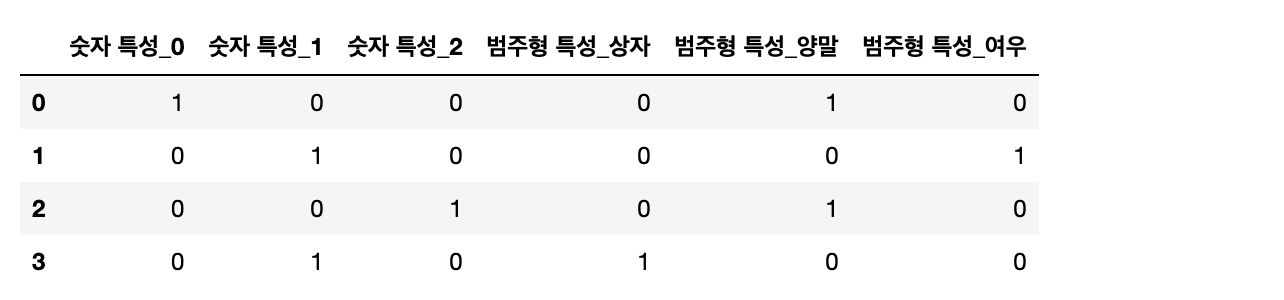
지금까지 원 핫 인코딩에 대하여 알아보았습니다.
다음 포스팅에서는 구간분할과 이산화 그리고 상호작용과 다항식에 대하여 알아보도록 하겠습니다!
'Programming > 특성 공학' 카테고리의 다른 글
| [Machine Learning]지도 학습 (0) | 2023.04.14 |
|---|---|
| [데이터 전처리]수치 변환 (1) | 2023.04.04 |
| [Machine Learning]일변량 통계 (0) | 2023.03.28 |
| [데이터 전처리]구간분할과 이산화 & 상호작용과 다항식 (0) | 2023.03.21 |
| [데이터 전처리]정규화(Normalisation)와 스케일 조정 (0) | 2021.04.07 |