이번 포스팅에서는 지난 포스팅에 이어서 pivot 테이블을 활용한 범죄 데이터 정리를 해보도록 하겠습니다.
csv 파일을 불러오는 방법은 아래 포스팅에서 더욱 자세하게 설명을 해두었으니 참고하시면 됩니다~!
[Python] Pandas를 활용한 파이썬에서 csv, excel 파일 읽어오기
이번 포스팅에서는 Pandas를 활용한 파이썬에서 csv, excel 파일 읽어오는 방법에 대해서 알아보도록 하겠습니다. pandas를 이용해 csv 파일을 불러오기 위해서는 아래와 같이 pandas를 먼저 import 해야
yuja-k.tistory.com
우선, 저장해둔 범죄 데이터.CSV 를 불러오도록 하겠습니다.

pandas의 pivot table을 사용하여, 데이터를 구별하고 정리할 수 있을 것 같습니다.
이때, 우리가 원하는 것은 구별 범죄 발생 횟수와 검거 횟수의 합이기 때문에 이전 포스팅에서 배운 aggfunc=np.sum도 사용해야 합니다.
aggfunc=np.sum에 대한 설명은 아래 포스팅을 참고하시면 됩니다~!
[Python] pivot_table을 활용해 원하는 기준 만들기
이번 포스팅에서는 pandas의 pivot_table을 활용해 원하는 기준을 만들어 보도록 하겠습니다. pivot table을 이용해 우리가 할 수 있는 것? pivot 테이블의 가장 큰 목
yuja-k.tistory.com
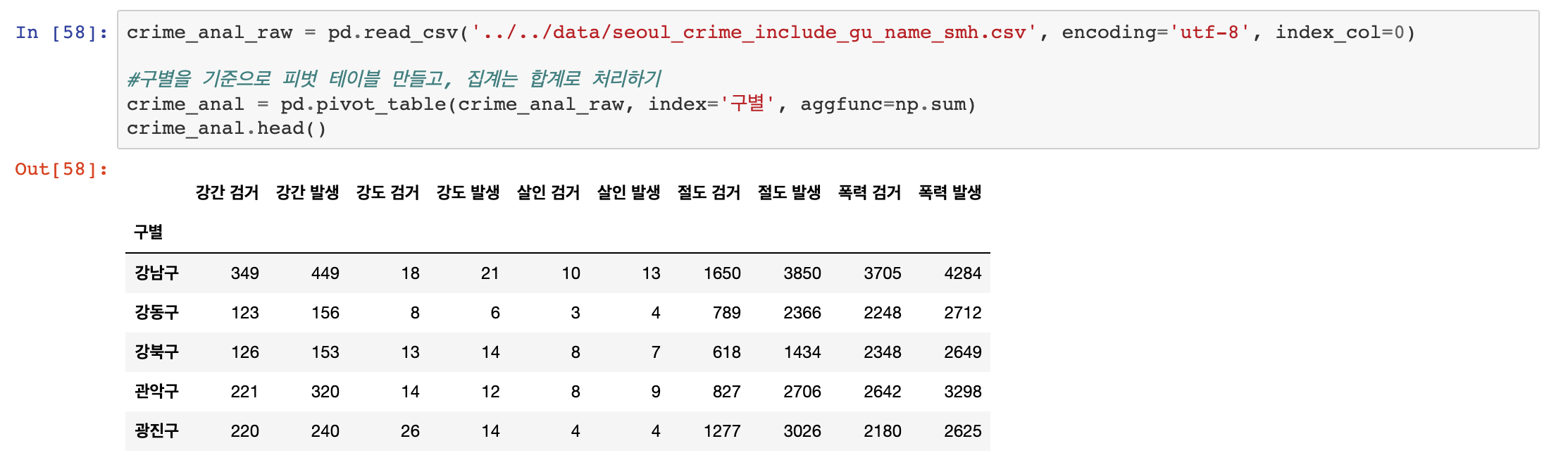
aggfunc=np.sum을 활용하여 매우 손쉽게 데이터가 정리 되었습니다!
다음은 범죄에 대한 검거율을 계산 해보겠습니다.
검거 횟수 / 범죄 발생 횟수 * 100을 해주면 검거율을 구할 수 있습니다.
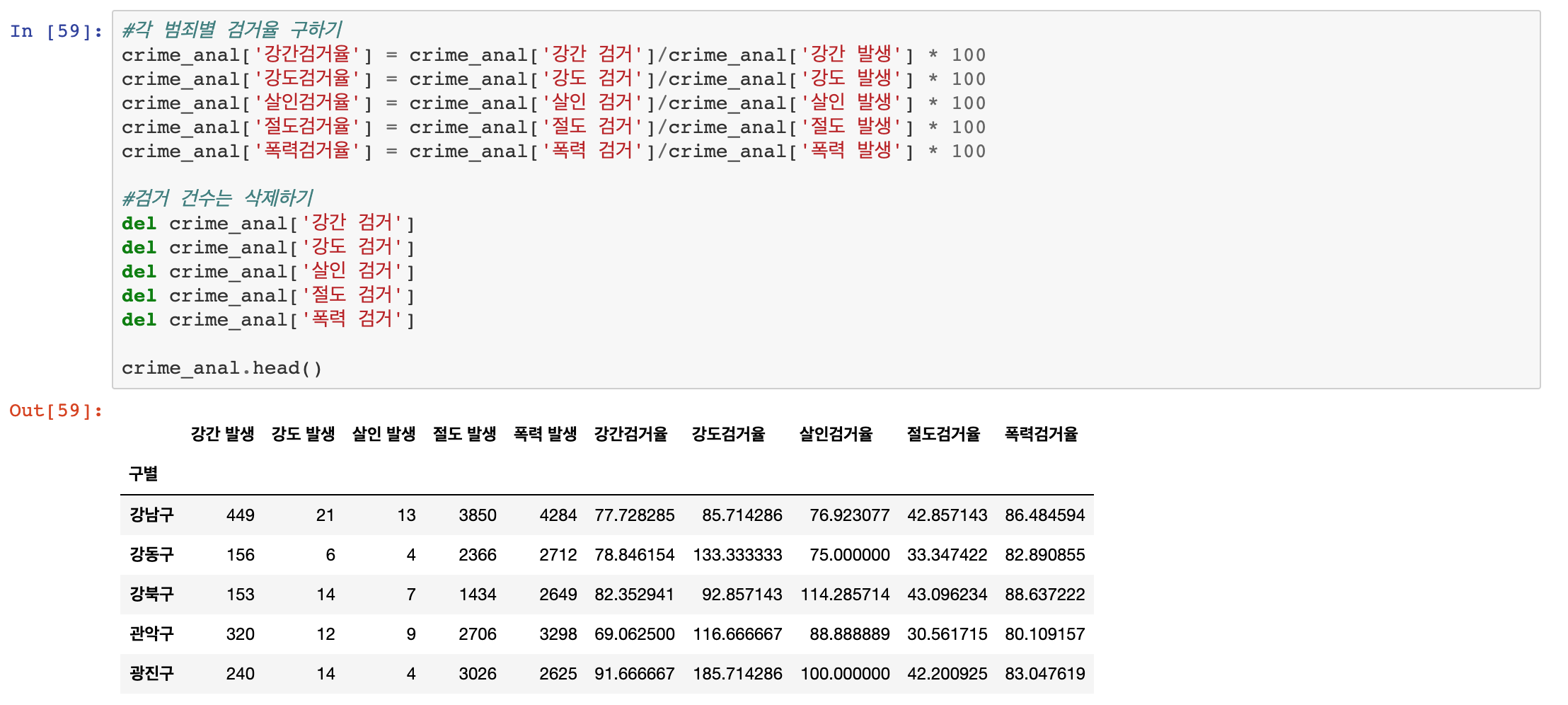
여기서! 검거율을 구했다면, 더 이상 검거 건수는 검거율로 대체할 수 있기 때문에 각종 범죄에 대한 검거 컬럼은 삭제합니다.
그런데 검거율이 100이 넘어버리는 곳도 있습니다. 왜냐하면, 전년도에 발생한 검거 건수도 포함되어서 그렇습니다.
그렇기 때문에 검거율이 100이 넘는 경우는 그냥 100으로 통일하겠습니다.

뒤에 붙은 발생이라는 단어도 삭제해 줍시다. 쉽게, rename 함수를 사용해서 바꿔보도록 하겠습니다.

데이터 표현을 위해 데이터를 다듬자! - 정규화(normalize)
데이터를 확인해 보면 강도와 살인 데이터는 2 자릿수 데이터지만, 절도와 폭력은 네 자릿수 데이터입니다.
숫자 자체로도 중요한 데이터지만, 각각의 범죄 발생 건수를 비슷한 범위에 놓고 비교하는 것이 편리할 때가 있습니다.
절도 1건이 살인 1건과 같지는 않습니다.
하지만, 각 항목의 최대 값을 1로 계산하여 그 비중 자체로 이야기하는 것이 쉽게 볼 수 있어, 데이터를 분석하기에도 편합니다.
추후 범죄 발생 건수를 종합적으로 비교하기 위해 우리는 각 컬럼 별로 데이터를 정규화해보겠습니다.
머신러닝 모듈 사용하기 sklearn
파이썬의 머신러닝 모듈인 sklearn의 preprocessing 기능을 활용하면 손쉽게 최댓값과 최솟값을 비교하면서 정규화를 진행할 수 있습니다.

CCTV 데이터와 합쳐봅시다
1장에서 했었던 인구수와 CCTV의 관계를 다시 떠올려 봅시다. 1장에서 했었던 내용은 범죄와는 전혀 상관없는 내용이었습니다.
하지만 지금은 이야기가 달라졌죠. 구별 CCTV와 인구수를 가져와서 범죄율과 얼마나 상관성이 있는지 확인해보겠습니다.

다음은 모든 범죄에 대한 정규화된 발생 건수를 합쳐서 통합적인 범죄에 대한 관리까지 진행하겠습니다.
이전에서 정규화를 진행하였기 때문에 범죄에 대한 총합을 관리 하기가 매우 수월해졌습니다.(물론 범죄의 경중을 논하는 게 아닙니다)

마찬가지로 검거율도 통합하겠습니다. (추후 검거 평균을 내기 위해 사용합니다)
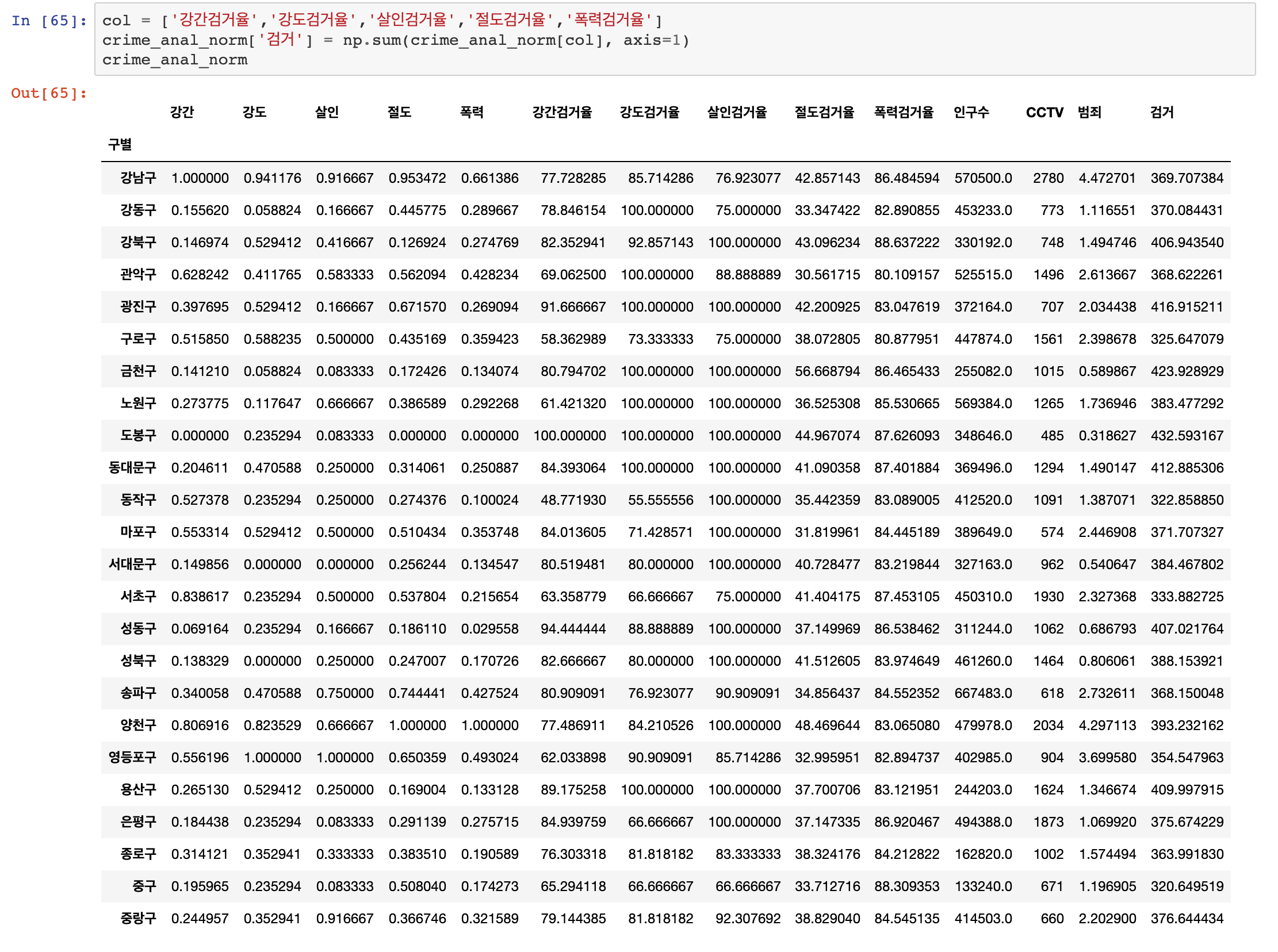
데이터를 모두 다 완성시켰습니다.
구별로 각종 범죄들이 정규화되어 있고, 범죄별 검거율 및 통합 검거율까지 완벽하게 들어갔습니다.
이번 포스팅을 통해서는 pivot 테이블을 활용하여, 범죄 데이터의 각 컬럼별로 데이터를 정규화를 통해 정리해보았습니다.
이제 시각화를 해볼 텐데, 다음 포스팅에서 Seaborn이라는 도구를 사용해서 분석해보도록 하겠습니다.
'Programming > 통계 데이터 분석' 카테고리의 다른 글
| [Python]Seaborn을 이용한 범죄데이터 시각화 (0) | 2021.04.06 |
|---|---|
| [Python] pivot_table을 활용해 원하는 기준 만들기 (0) | 2021.04.02 |
| [Python] CCTV 현황 그래프로 분석하기 (0) | 2021.04.01 |
| [Python]CCTV 데이터와 인구 현황 데이터를 합치고 분석하기 (0) | 2021.02.18 |
| [Python] 서울시 CCTV data와 인구현황 data 파악하기 (0) | 2021.02.15 |