지난 블로그, 행렬과 신경망에 대하여 알아보았습니다.
2023.08.30 - [Programming/Deep Learning] - [Python/DeepLearning] #5. 행렬과 신경망
[Python/DeepLearning] #5. 행렬과 신경망
지난 블로그에서는 차원의 수에 관련하여 알아보았습니다. 2023.08.23 - [Programming/Deep Learning] - [Python/DeepLearning] #4. 다차원 배열의 계산 [Python/DeepLearning] #4. 다차원 배열의 계산 지난 블로그에서는
yuja-k.tistory.com
이번 시간에는 신경망의 출력층에 대하여 알아보고 설계를 해보도록 하겠습니다~!
신경망의 사용처
신경망은 분류와 회귀 모두 사용할 수 있습니다.
다만 둘 중 어떤 문제냐에 따라 출력층에서 사용하는 활성화 함수가 달라집니다!
일반적으로 회귀에서는 항등함수, 분류에서는 소프트맥스 함수를 사용합니다.
항등 함수(Identity Function)와 소프트맥스 함수(Softmax Function) 구현해 볼까요?
출력층의 활성화 함수
- 이진 분류(Binary Classification) : 𝑠𝑜𝑓𝑡𝑚𝑎𝑥, 𝑠𝑖𝑔𝑚𝑜𝑖𝑑 함수를 주료 사용
- 다중 분류(Mulitple Classification) : 𝑠𝑜𝑓𝑡𝑚𝑎𝑥
보통 전천후 함수로 𝑠𝑜𝑓𝑡𝑚𝑎𝑥 함수를 주로 사용하는 추세이고, 𝑠𝑖𝑔𝑚𝑜𝑖𝑑를 출력층의 활성화 함수로 사용할 때는 출력층의 뉴런은 한 개로 설정한다.
출력층에서 사용하는 활성화 함수인 항등함수는 정말 쉽습니다.
일전에도 살펴봤지만, 입력한 값을 그대로 출력값으로 내보내면 됩니다.
한편, 분류에서 사용되는소프트맥스의 식은 다음과 같습니다.

여기서 𝑒𝑥𝑝(𝑥))는𝑒𝑥을 뜻하는 지수함수입니다.
𝑛은 출력층의 뉴런의 개수이며, 𝑦𝑘는 출력층 뉴런의𝑘 번째 출력을 의미합니다.
소프트맥스 함수의 분자는 출력층으로 입력되는 입력값 𝑎𝑘로 구성되며, 분모는 모든 입력값의 지수 함수의 합으로 구성됩니다.
계속해서 소프트맥스 함수를 직접 구현해 보도록 하겠습니다. 먼저 원리부터 살펴보겠습니다.
# softmax 함수 구현하기 - 원리
import numpy as np
a = np.array([0.3, 2.9, 4.0]) # 입력 신호
# 분자 계산
exp_a = np.exp(a) # 모든 입력 신호에 대한 지수 함수 적용 (분자 값)
print("각 입력 함수에 대한 지수 함수 적용 결과 : {}".format(exp_a))
# 분모 계산
sum_exp_a = np.sum(exp_a) # 분모가 될 모든 입력 신호에 대한 지수 함수의 합
print("softmax 함수의 분모값 : {}".format(sum_exp_a))
# 소프트맥 계산, numpy 배열 형태로 등장하기 때문에 한꺼번에 계산 가능
y = exp_a / sum_exp_a
print("softmax 결괏값 : {}".format(y)) # 각 입력 값 별 softmax 결괏값각 입력 함수에 대한 지수 함수 적용 결과 : [ 1.34985881 18.17414537 54.59815003]
softmax 함수의 분모값 : 74.1221542101633
softmax 결괏값 : [0.01821127 0.24519181 0.73659691]
print("softmax 결괏값의 총 합 : {}".format(np.sum(y)))softmax 결괏값의 총 합 : 1.0
복잡해 보였던 소프트맥스 함수의 식을 파이썬으로 표현해 보았습니다.
생각보다 어렵진 않죠? 그럼 직접적으로 소프트맥스 함수를 구현해 보겠습니다.
# 𝑠𝑜𝑓𝑡𝑚𝑎𝑥 함수 직접 구현
def softmax(a):
exp_a = np.exp(a)
sum_exp_a = np.sum(exp_a)
y = exp_a / sum_exp_a
return ysoftmax(a)
𝑠𝑜𝑓𝑡𝑚𝑎𝑥 함수 튜닝하기
소프트맥스 함수는 지수 함수를 사용합니다.
따라서 입력 값이 약간만 커져도 굉장히 큰 값을 연산해야 합니다.
예를 들어 𝑒10=20,000 정도이고, 𝑒100은 0이 40개 넘는 수, 보통 𝑒10001000은 무한대를 의미하는 𝑖𝑛𝑓를 만들어 냅니다.
또한 이렇게 큰 값으로 나눗셈을 하면 수치가 '불안정'해지기 마련입니다.
따라서 이 문제를 해결하기 위해 소프트맥스 함수를 약간 개선해 줄 필요가 있습니다.
log의 개념을 활용하면 손쉽게 처리가 가능합니다!
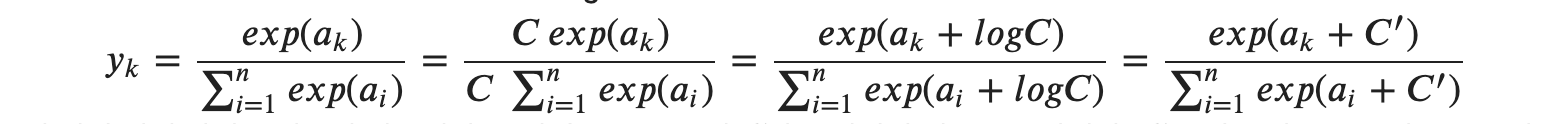
위 식의 전개 과정은 다음과 같습니다.
1. 분자와 분모 모두에 𝐶라는 임의의 정수를 곱합니다.
2. 𝐶를 지수 함수 exp 안으로 옮겨서 𝑙𝑜𝑔𝐶로 만들어 줍니다.
3. 𝑙𝑜𝑔𝐶를 𝐶′′라는 새로운 기호로 바꿔 줍니다.
소프트맥스 함수의 지수 함수를 계산할 때 어떤 정수를 더하거나 빼도 결과는 바뀌지 않습니다.
여기서 𝐶′에 어떤 값을 대입해도 상관은 없지만, 오버플로를 막을 목적으로는 입력 신호들 중 최댓값을 이용하는 것이 일반적입니다.
다음 예를 살펴보겠습니다.
big_a = np.array( [1010, 1000, 990] )
print(softmax(big_a)) # 소프트맥스 함수 계산
너무 큰 숫자를 계산하는 바람에 모든 값에 NaN 이 출력되는 것이 확인됩니다.
입력 특성의 최댓값을 𝐶′으로 집어넣어서 계산해 보겠습니다.
overflow 발생 원인
𝑒𝑥𝑝함수는 지수함수이다. 𝑒10 은 약 20,000이고,𝑒100은 0이 40개 넘어가고, 𝑒1000은 컴퓨팅 시스템에서 무한대를 의미하는 𝑖𝑛𝑓를 의미한다.
해결하기 위해서는 𝑙𝑜𝑔를 활용한다. 참고로 지수함수에서의 𝑙𝑜𝑔는 뺄셈을 의미한다.

- 분자와 분모에 𝐶라는 임의의 정수를 곱합니다.
- 𝐶를 지수 함수 𝑒𝑥𝑝안으로 옮겨서 𝑙𝑜𝑔𝐶로 만들어 준다.
- 𝑙𝑜𝑔𝐶를 𝐶′′이라는 새로운 기호로 바꿔준다.
# 보통 상수 C는 입력값 중에 제일 큰값으로 선정한다.
c = np.max(big_a)
print(big_a-c)
print(np.exp(big_a-c) / np.sum(np.exp(big_a-c)))
정상적으로 잘 구해지는 것이 확인됩니다!
이를 토대로 소프트맥스 함수를 다시 정의해 보겠습니다.
def softmax(a):
c = np.max(a) # 상수 c 구하기( 입력의 최댓값 ) c=1010
exp_a = np.exp( a - c ) # a + log C ; 각 원소마다 차를 구함 " overflow 대책 "
sum_exp_a = np.sum(exp_a)
y = exp_a / sum_exp_a
return y
big_y = softmax(big_a)
print("softmax 결과 : {}".format(big_y))
print("softmax 총합 : {}".format(np.sum(big_y)))
𝑠𝑜𝑓𝑡𝑚𝑎𝑥 함수의 특징
소프트맥스 함수를 사용하면 다음과 같이 신경망의 출력을 계산할 수 있습니다.
y = softmax(a)
print("softmax 결과 : {}".format(y))
print("softmax 총합 : {}".format(np.sum(y)))
소프트맥스 함수 결괏값 배열의 원소들은 항상 0과 1 사이의 실수입니다.
가장 중요한 성질은 소프트맥스 함수의 출력 총합은 1이라는 것입니다.
총합이 1이 된다는 점이 소프트맥스 함수의 가장 중요한 성질입니다.
이 성질 덕분에 소프트맥스 함수의 출력을 '확률'로 재해석할 수 있습니다.
위의 결과물을 예시로 들자면, "y [0]의 확률은 약 1.8%, y [1]의 확률은 24.5%, y [2]의 확률은 73.7%로 해석 가능하며,
- 약 74% 확률로 2번째 클래스, 25%의 확률로 1번째 클래스, 1%의 확률로 0번째 클래스이다.
라는 식으로 확률적인 결론을 낼 수 있게 됩니다.
즉, 소프트맥스 함수를 이용함으로 인해 문제를 확률적(통계적)으로 대응할 수 있게 되는 것입니다.
여기서 주의할 점으로, 소프트맥스 함수를 적용해도 각 원소의 대소 관계는 변하지 않습니다.
이는 지수 함수 𝑦=𝑒𝑥𝑝(𝑥)가 단조함수( 정의역 원소 a, b가𝑎≤𝑏 일 때, 𝑓(𝑎)≤𝑓(𝑏)가 되는 함수)이기 때문입니다.
실제로 앞의 예에서의 a의 원소들 사이의 대소 관계가 y의 원소들 사이의 대소 관계로 그대로 이어지는 것이 확인됩니다.
신경망을 이용한 분류에서는 일반적으로 가장 큰 출력을 내는 뉴런에 해당하는 클래스로만 인식됩니다.
그리고 소프트맥스 함수를 적용해도 출력이 가장 큰 뉴런의 위치는 변화되지 않습니다.
결과적으로 신경망으로 분류할 때는 출력층의 소프트맥스 함수를 생략해도 됩니다.
실제 현업에서도 지수 함수 계산에 드는 자원 낭비를 줄이고자 소프트맥스 함수를 생략하는데요, 그렇다면 왜 소프트맥스 함수를 배웠을까요?
이는 기계학습의 문제 풀이는 학습과 추론 두 단계를 거치기 때문입니다.
학습 단계에서 모델을 학습하고, 추론 단계에서 앞서 학습한 모델로 미지의 데이터에 대해서 추론(분류)을 수행하게 됩니다.
이때, 추론 단계에서는 소프트맥스 함수를 생략하는 것이 일반적입니다만, 신경망을 학습시킬 때는 출력층에서 소프트맥스 함수를 사용하게 됩니다. 신경망을 학습시킨다는 개념은 조금 나중에 이야기하도록 하겠습니다.
다음 블로그에서는 출력층의 뉴런 수 정하는 방법과 Tensorflow MNIST 데이터를 불러와서 형상 다루는 방법에 대하여 알아보도록 하겠습니다!
'Programming > Deep Learning' 카테고리의 다른 글
| [Python/DeepLearning] #8. 손실 함수의 종류(Loss Function) (1) | 2024.01.27 |
|---|---|
| [Python/DeepLearning] #7. 출력층 뉴런 개수 정하기 & MNIST 데이터(Via Tensorflow) (1) | 2023.11.03 |
| [Python/DeepLearning] #5. 행렬과 신경망 (0) | 2023.08.30 |
| [Python/DeepLearning] #4. 다차원 배열의 계산 (0) | 2023.08.23 |
| [Python/DeepLearning] #3. 활성화 함수의 기본 (0) | 2023.08.18 |