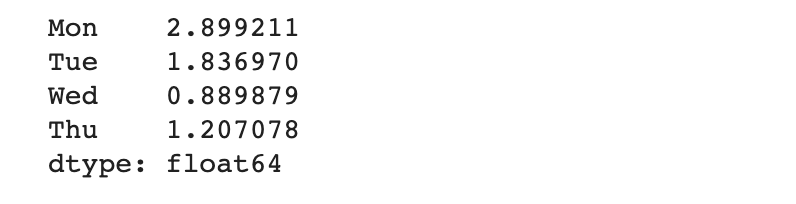이번 포스팅에서는 pandas의 pivot_table을 활용해 원하는 기준을 만들어 보도록 하겠습니다.
pivot table을 이용해 우리가 할 수 있는 것?
pivot 테이블의 가장 큰 목적은우리가 원하는 기준을 만들어 활용한다는 것입니다.
컴퓨터 부품 판매 데이터를 예제로 사용해보겠습니다.
위의 데이터에서가게명(Name)으로 정렬해서 확인하고 싶을 때pivot_table을 활용할 수 있습니다.
Name이 인덱스가 되고, 나머지 값들은 기본적으로평균값을 표현하게 됩니다.
여기서 인덱스는 이름 말고도 여러 개로 지정해 줄 수 있습니다.
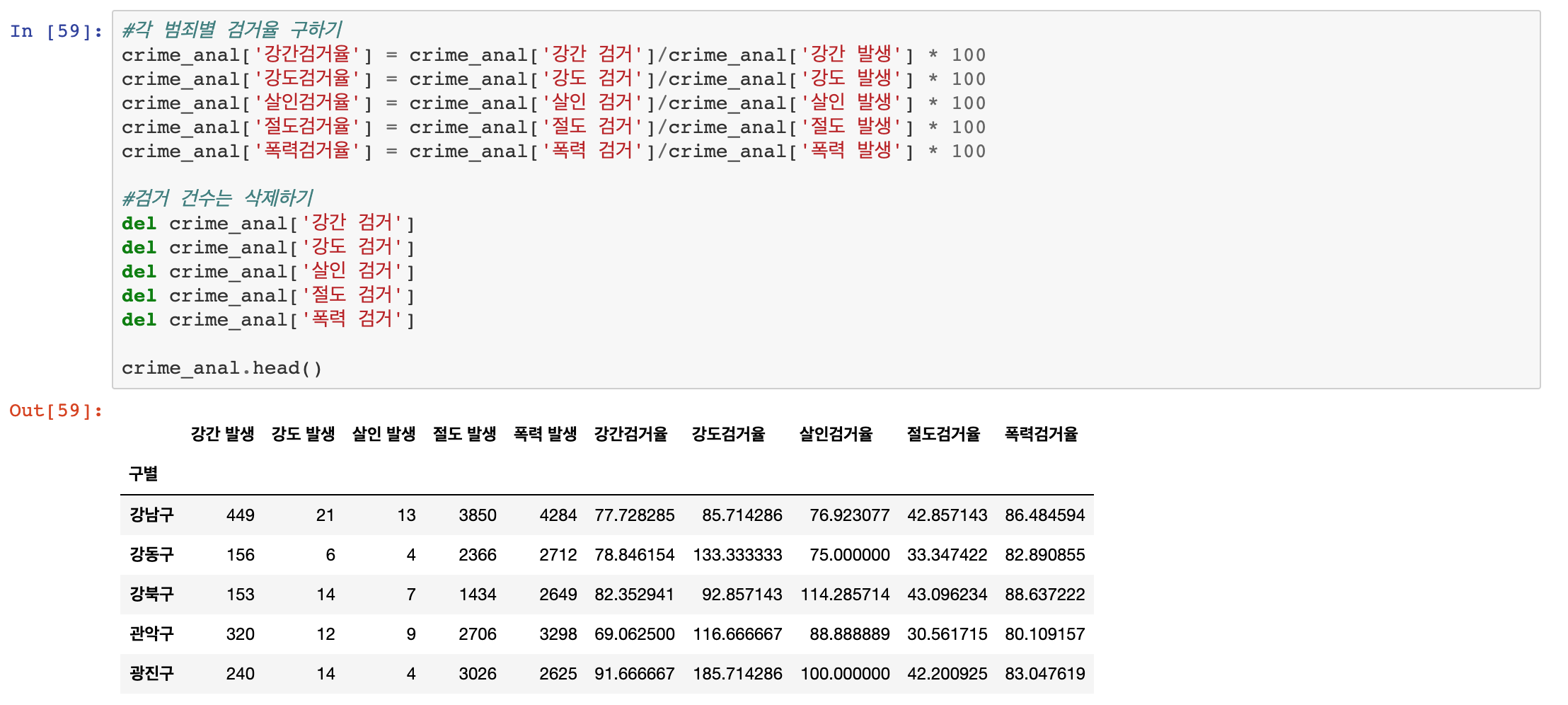
특정 Value만 선택해서 계산을 할 수도 있습니다.
기본적으로 value 자체를 pivot_table로 합치면평균이 됩니다만,aggfunc(집계 기능) 옵션을 활용하여 합계를 계산할 수도 있습니다. numpy의 sum(np.sum) 함수를 지정하면 됩니다.
aggfunc를 적절히 이용하면 평균과 합계 등 여러 가지 데이터를 그럴싸하게 보여 줄 수도 있습니다.
pivot table은 언제 써야 할까요?
pivot 테이블 자체는 그리 큰 비중을 차지하지는 않습니다. 하지만 원하는 데이터를 구해내기 위해서 조건문과 반복문을 생각하면 어떻게 될까요? 꽤나 머리 아픈 작업이 될 것 같습니다. 일일이 다 코드로 원하는 데이터를 구해내기보다, pivot table을 사용하여 원하는 데이터를 어떻게 뽑아낼지 테스트해 보고, 구현하는 연습이 많이 필요합니다.
드디어 matplotlib를 이용해 데이터를 시각화해 줄 수 있지만, 아직 한글 처리 문제가 남아있습니다. 기본적으로 matplot은 한글 폰트를 지원하지 않기 때문에 matplotlib의 폰트부터 변경시켜 보겠습니다. 순서는 다음과 같습니다.
platform 모듈 임포트 하기
OS를 구분 해 줄 수 있습니다.
matplotlib 모듈 임포트 하기
시각화를 하기 위함이겠죠?
OS를 구분하여 폰트를 각각 설정해 줍니다.
폰트 설정이 끝났으면 다시 한번 결과를 확인해보겠습니다.
pandas 데이터에 바로 plot 명령을 이용해 데이터를 바로 그려 볼 수 있습니다.
예쁘고 쉬운 보기를 위해서 정렬을 해보도록 하겠습니다!
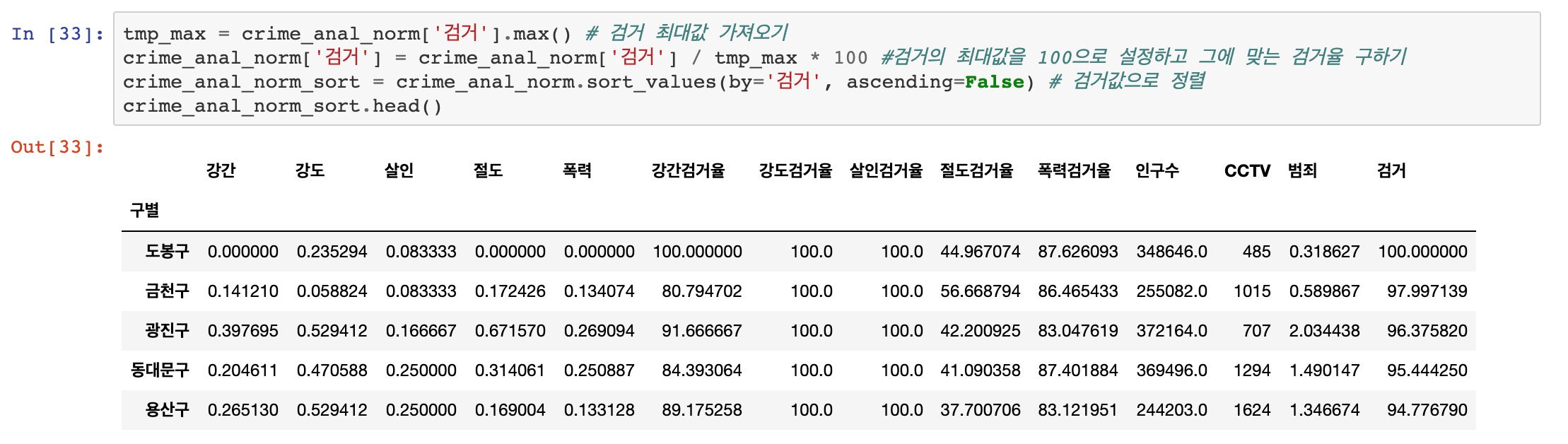
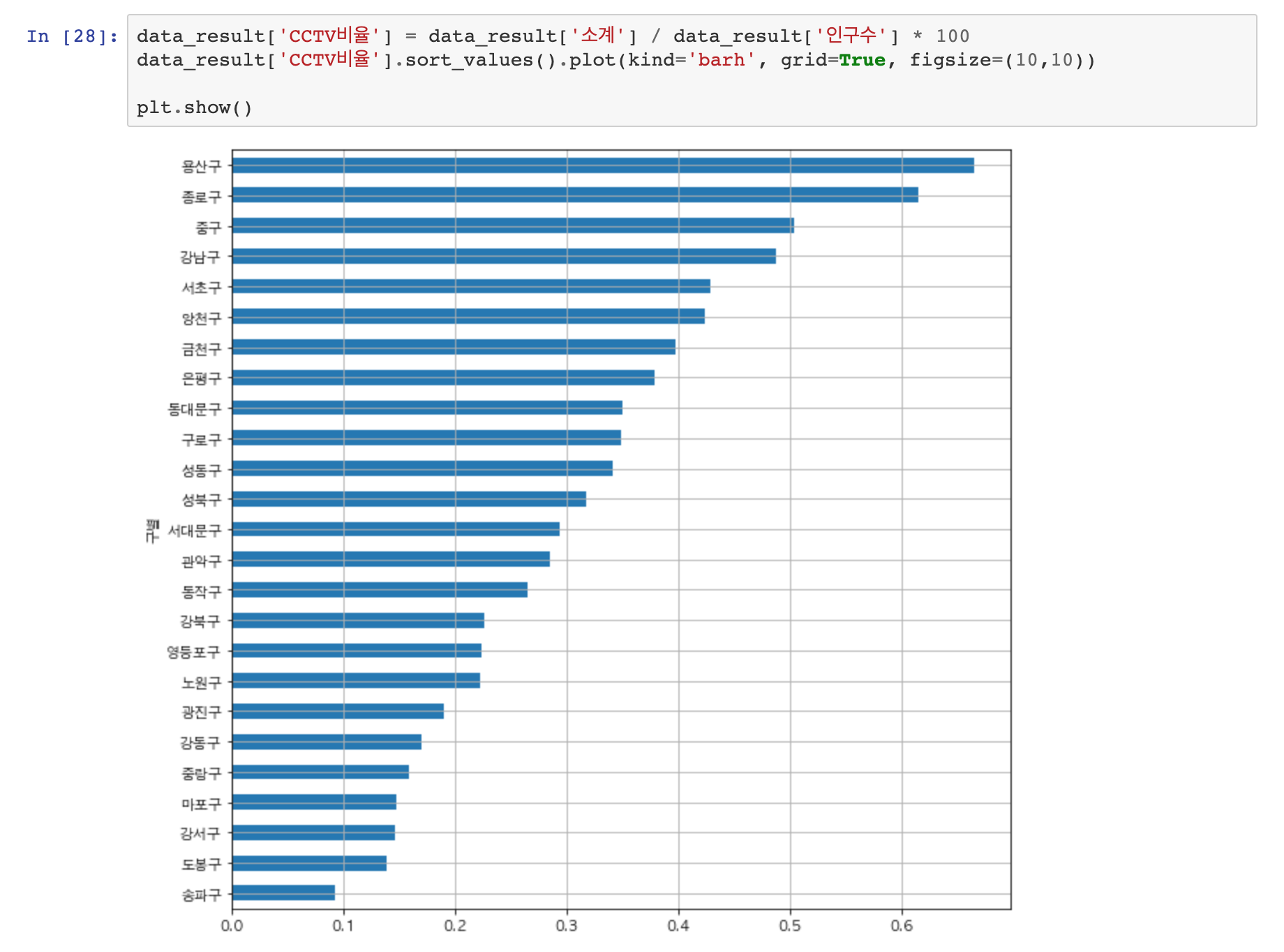
이제! 시각화가 되었으니 다시 한번 분석을 해보도록 하겠습니다. 이번엔 비율입니다!
먼저 시각화가 되어있는 그래프를 보면 CCTV 개수 자체는 강남구가 월등하게 많은 것을 할 수 있습니다.. 또한 가장 CCTV가 많이 없는 그룹도 알 수 있죠? 이어서 인구 대비 CCTV 비율을 계산해보도록 하겠습니다. 간단하게 소계 / 인구 * 100을 하면 될 것 같습니다.
인구수 대비 CCTV 수는 용산구와 종로구가 제일 많은 것을 알 수 있습니다. 송파구는 여전히 인구수로 비교하나, 소계로 비교하나 최하위권을 차지하고 있는 것을 확일 할 수 있습니다.
어느 정도 분석은 된 것 같지만 조금 더 자세히 시각화를 해보도록 하겠습니다. scatter를 활용해 보도록 합시다!
표시한 데이터를 대표할 수 있는 직선을 하나 그려보도록 하겠습니다.
직선의 용도는 인구수가 많아질수록 CCTV의 설치량은 많이 지는 것을 한눈에 알아볼 수 있게 해 줍니다. ( 방금 전의 비율과는 무관합니다~!)
그리고 지금 그려보는 직선은 인구별 CCTV에 대한 기준이 된다고 보시면 됩니다.
이제 이 그래프의 직선은 구별 CCTV의 기준값이 됩니다. 이때, 우리가 기준으로 삼을 수 있는 조선은 이 직선에 가장 근접한 점을 찾아보면 됩니다.
확인을 해보니 대략 300,000만 명의 인구수일 때, 1,100개의 CCTV가 기준이 된다!라고 볼 수 있습니다.
그렇다면 이 직선을 기준으로 해서 멀리 떨어져 있다는 것은 비정상적으로 많다/ 적다 라는 것입니다.
직선보다 위에 있을수록 CCTV가 인구수에 비해 과하게 설치가 되었다
직선보다 아래 있을수록 CCTV가 인구수에 비해 부족하다
직선과 멀리 떨어질수록 생산도 다르게 표현해주고, 기준점에서 많이 벗어난 구의 이름을 표시해 보도록 하겠습니다.
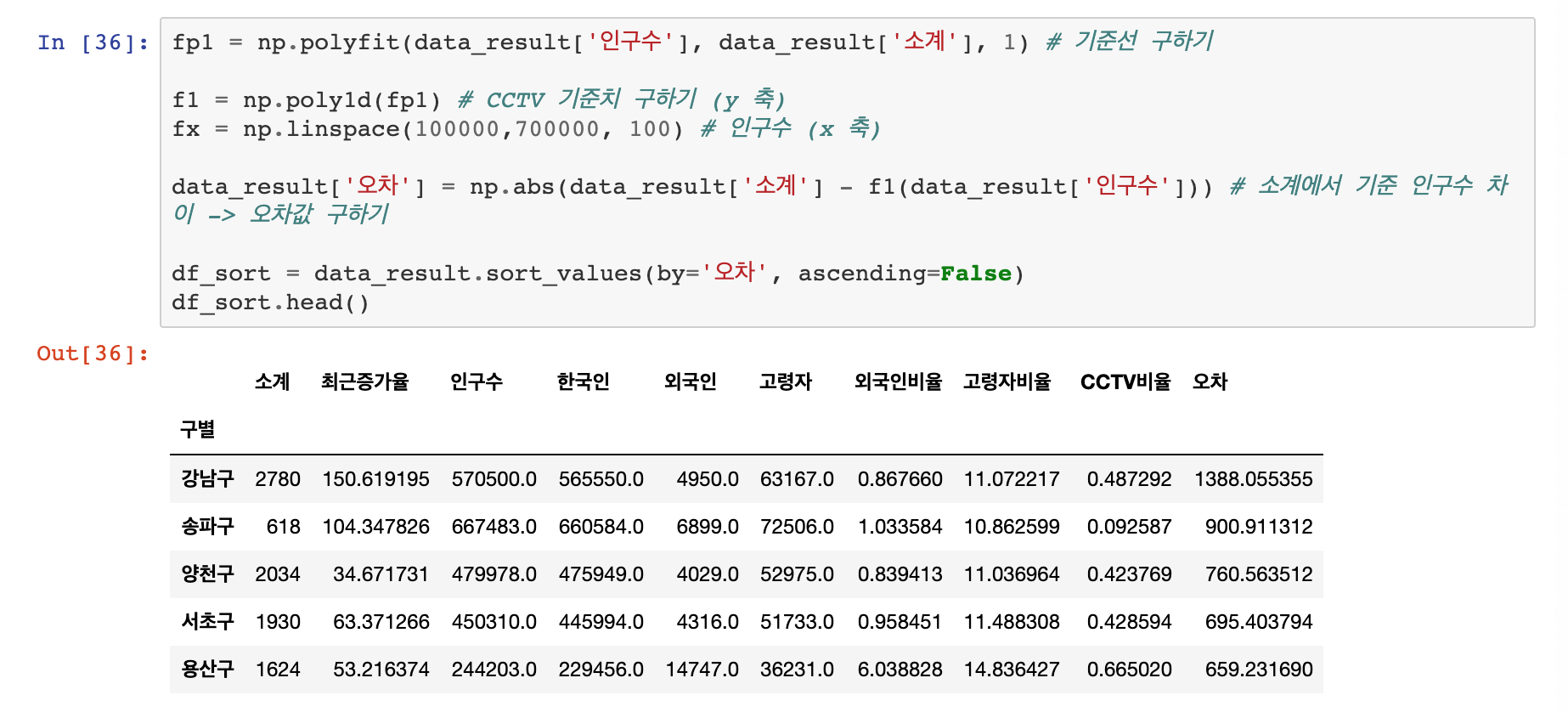
따라서 직선과의 오차를 구하는 코드를 작성하고, 오차가 큰 순으로 데이처를 정렬해서 그래프를 그려보도록 하겠습니다.
결론
직선을 기준으로, 위에 있는 강남구, 양천구, 서초구, 은평구, 용산구는 서울시 전체의 지역의 일반적인 경향보다 CCTV가 많이 설치되어있습니다.
그리고 송파구, 강서구, 중랑구, 마포구, 도봉구는 일반적인 경향보다 CCTV가 적게 설치된 지역입니다.
특히,
강남구는 월등히 많은 CCTV를 보유하고 있다
송파구는 매우 적은 CCTV를 보유하고 있다
라고 결론을 내릴 수 있습니다.
어려우셨나요? 사실 scatter그래프를 이용해서 분석 한 내용은 정말 고급스러운(어려운) 내용입니다.
다음 포스팅에서는 pandas의 pivot_table을 활용해 원하는 기준 만들기를 해보도록 하겠습니다.
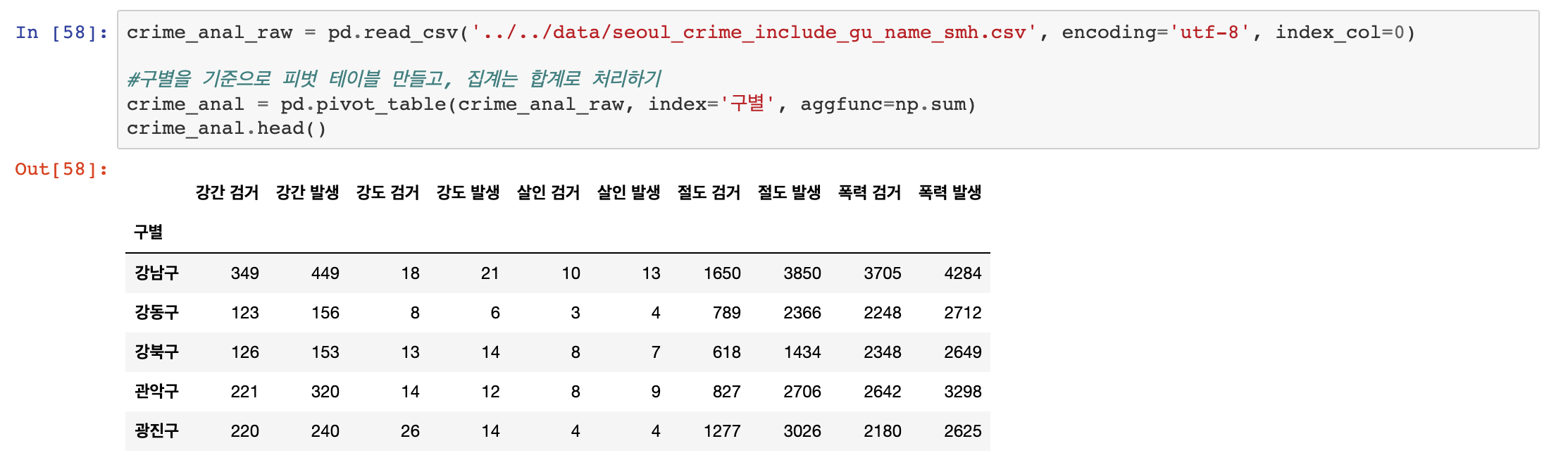
연도별 데이터는 이제 별 의미가 없기 때문에 삭제하겠습니다. row 행 데이터를 삭제할 때는 drop() 함수를 사용했었지만, column열 데이터(세로줄)를 삭제할 때는del키워드를 사용합니다.
숫자로 인덱스를 구분하는 것보다, unique 한 구별 데이터를 인덱스로 만들어 주는 것이 더 보기 좋습니다.
이러한 습관은 추후에 시각화에도 도움이 됩니다. set_index함수를 사용해서 인덱스를 변경할 수 있습니다.
어떤 데이터끼리 비교하는 것이 좋을까?
다양한 접근은 아직은 어려우나, 인구수의 어떤 데이터를 이용해서 CCTV를 비교할지를 결정 지어 주어야 합니다. 비교해 볼 수 있는 데이터는 고령자 비율, 외국인 비율, 인구수로 생각해볼 수 있는데, 어떠한 데이터를 CCTV와 비교할지를 결정 지어 줘야 할지를 결정짓는 것이상관계수 입니다. 상관계수의 절댓값이 클 수록 두 데이터는 긴밀한 관계를 갖는다고 생각 해 볼 수 있습니다. 상관계수에는 다음과 같은 법칙이 적용됩니다.
상관계수 절대값이 0.1 이하면 무시해야 하는 상관관계
상관계수 절대값이 0.3 이하면 약한 상관관계
상관계수 절대값이 0.7 이하면 뚜렷한 상관관계
상관계수 계산은 매우 어려우나 numpy 모듈의corrcoef함수를 이용하면 손쉽게 데이터끼리의 상관관계를 파악할 수 있습니다.
고령자 비율과 소계의 상관계수 구하기
기준 대각선(좌상-우하)을 제외한 나머지 데이터들만 확인하면 됩니다.
계속 이어서 상관 계수를 구해 보겠습니다.
외국인 비율과 소계의 상관계수 구하기인구수와 소계의 상관계수 구하기
상관계수 분석 결과 고령자 비율과 외국인 비율은 각각 0.2, 0.1 정도로 상관관계가 거의 없다고 판단이 됩니다. 하지만,인구수와 비교해봤을 때 0.3 이상으로써 약한 상관관계가 존재한다고 말할 수 있을 것 같습니다.
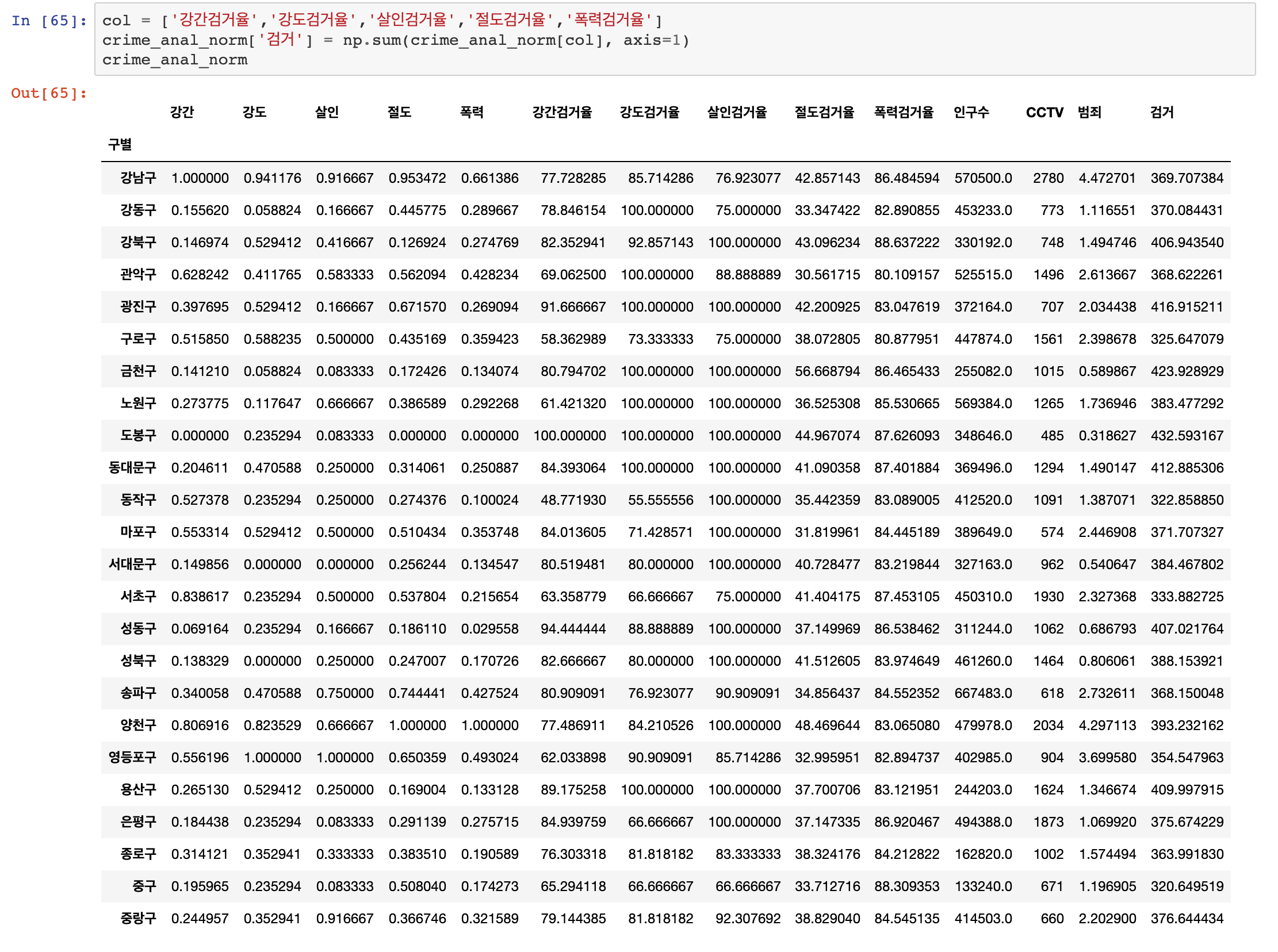
도봉구 < 마포구 < 송파구 < 중랑구 < 중구 순으로 CCTV가 제일 없다는 것을 확인할 수 있는데요, 추후구별 범죄율 분석을 진행할 때 다시 확인하겠지만 강남 3구 중 하나인송파구의 CCTV가 가장 적은 구 중 하나라는 것을 확인할 수 있습니다. 하지만송파구는 결코 범죄율이 낮지 않은 구이지만, CCTV가 적은 구 중 하나라는 사실만 알고 넘어갑시다
이어서 CCTV 개수가 가장 높은 순으로 내림차순을 진행해 보겠습니다.
CCTV가 제일 많은 곳은 강남구 > 양천구 > 서초구 > 은평구 > 용산구가 순서로 확인됩니다.
이어서 3년간 CCTV증가율을 구해서 3년간 CCTV가 제일 많이 증가한 구를 구해 보겠습니다.
최근 3년 치 CCTV 개수(2014~2016년) 더하고 2013년 이전 CCTV개수로 나누고 100 곱해서 증가율 구하기
결과를 보면 최근 3년간의 CCTV가 2013년 이전 대비 가장 많이 증가한 곳은
종로구 > 도봉구 > 마포구 > 노원구 > 강동구 순이라는 것을 알 수 있습니다.
이번에는 서울시 인구 데이터를 다뤄보겠습니다.
먼저 데이터를 다시 한번 확인해 보죠
0번 인덱스에 위치한 합계는 별로 필요 없는 데이터입니다. (구별 데이터가 중요하기 때문입니다.) 따라서 데이터 삭제 명령어를 이용해 보겠습니다.
drop()함수를 이용해 원하는 데이터를 삭제시킬 수 있습니다.
0번 인덱스에 위치하던 합계가 잘 삭제된 것이 확인됩니다. 이어서 지역구의 이름을 의미하는'구별' 컬럼이 유일한 컬럼(unique column)인지 확인해 봐야 할 것 같습니다. 이유는 혹시라도 중복된 구가 있으면 해당하는 구를 유일하게 만들어 데이터로써 무결하게 사용해야 하기 때문입니다.
unique()함수를 활용해 해당 컬럼의 데이터가 데이터 프레임에서 한번 이상 나타나 있는지 확인해 봅시다.
이를유니크 조사라고 합니다
다 잘 나온 것 같지만 문제는 제일 마지막에 nan이 있는 것이 확인됩니다.
nan데이터가 어디에 있는지 확인해 봅시다.
이때 사용할 수 있는 함수는isnull() 입니다.
26번 인덱스의 데이터가 전부다 NaN인 것이 확인했습니다.
합계처럼 저희에겐 필요 없는 데이터가 될 것 같습니다. 왜냐 하면 우리는 값이 있는 것들만 활용할 예정이기 때문입니다.
값이 없는 26번 인덱스의 데이터는drop()으로 삭제하겠습니다.
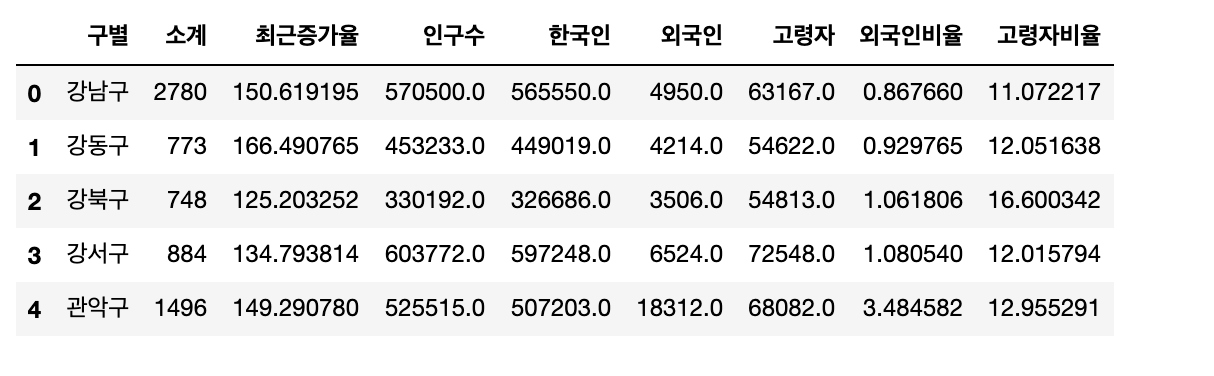
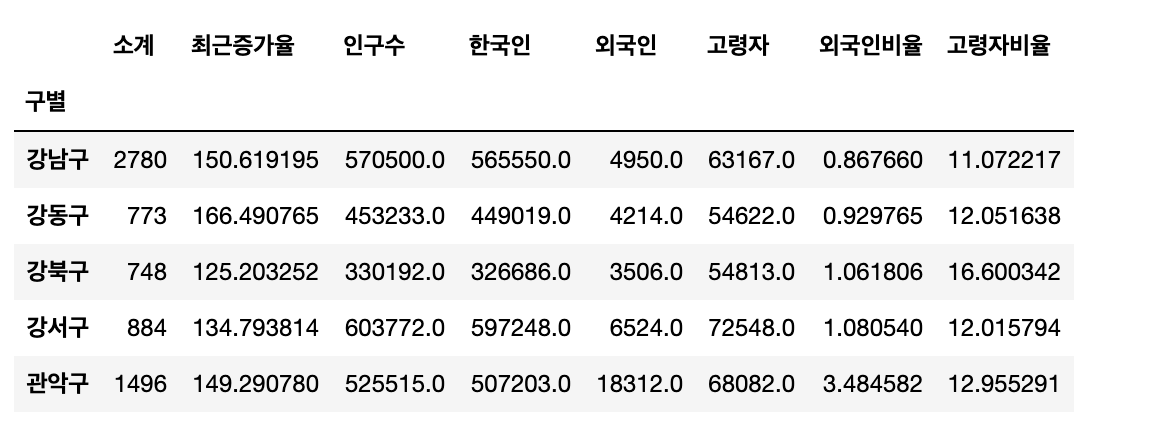
이제부터 본격적으로 구별 전체 인구를 활용해서 먼저 '외국인 비율'과 '고령자 비율'을 계산해 보겠습니다.
각종 기준을 토대로 정렬해서 데이터를정렬만해보겠습니다. 지금부터 정렬할 기준들은 다음과 같습니다. 인구수, 외국인, 외국인 비율, 고령자, 고령자 비율
여기까지는 그냥 컬럼 다루기와 정렬하는 연습일까?
열심히 외국인 비율 및 고령자 비율 만들고 그다음 정렬하는 코드도 다시 한번 실습해 보았습니다. 사실 여기까지는 정말연습이긴 합니다만
여기에서도 아주 간단하게 데이터를 분석할 수 있습니다.
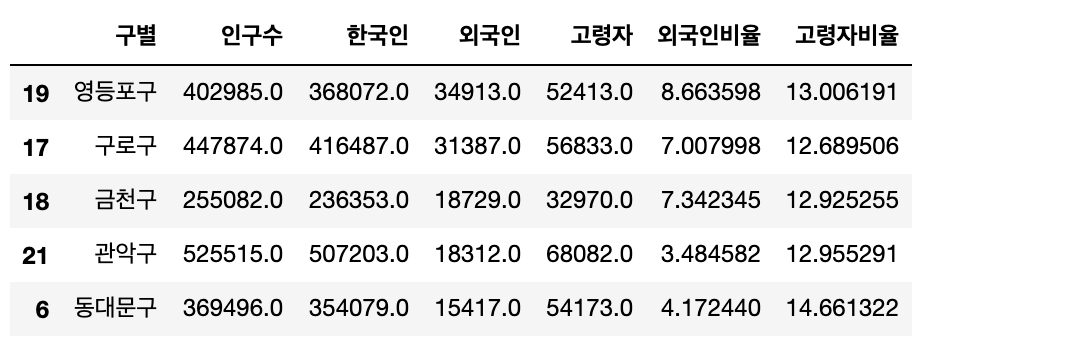
인구수가 제일 많은 5 지역은 송파구, 강서구, 강남구, 노원구, 관악구 순입니다.
외국인이 제일 많은 5 지역은 영등포구, 구로구, 금천구, 관악구, 동대문구 순입니다.
하지만외국인 비율이 제일 많은 5 지역은 영등포구, 금천구, 구로구, 중구, 용산구로 외국인 인구수와는 약간 다릅니다.
고령자가 제일 많은 5 지역은 강서구, 송파구, 은평구, 노원구, 관악구 순입니다.
하지만고령자 비율이 제일 많은 5 지역은 강북구, 종로구, 중구, 용산구, 서대문구 순입니다.
이를 토대로 우리가 알 수 있는 것은 무엇일까요?
아직 데이터를 시각화하거나 하는 과정은 하지 않았지만, 몇 가지 생각은 해 볼 수 있을 것 같습니다.
인구수가 제일 많은 지역은 송파구이지만, 영등포구가 제일 외국인이 많다. 그리고 그 근처라고 할 수 있는 구로구, 금천구 등도 굉장히 외국인이 많다.
송파구는 고령자가 제일 많지만 고령자의 비율이 높지 않은 것이 확인된다. 하지만 강북구, 종로구, 중구, 용산구, 서대문구 같은 경우는 인구수 대비 고령자 비율이 많기 때문에 추후 고령화가 우려된다.
같은 형식으로 데이터 분석이 가능하겠네요.
하지만 아직 CCTV와 인구수는 전혀 관련 없잖아요?
다음 포스팅부터두 데이터를 병합해서 분석해 보겠습니다. 인구 대비 CCTV 현황을 분석 해 보겠습니다. pandas 고급 사용법으로 이어서 넘어가도록 하겠습니다.
pandas는 기복적으로 python에서 데이터를 읽어와서 손쉽게 활용할 수 있게 해주는 모듈입니다.
이때 불러온 데이터를 데이터 프레임(Data Frame)이라고 합니다.
numpy - 통계 수식 등 수학에 많이 사용되는 라이브러리 -> pandas 와 numpy는 같이 쓰일 때가 많다.
Series는 pandas의 가장 기본적인 자료형입니다.
list 형태로 데이터를 구성하여 data frame을 간단하게 만들 수 있습니다.
pandas의 series 자료형은 파이썬의 리스트로 이루어진 여러 데이터를 한꺼번에 관리 할 수 있다.
날짜 데이터 생성하기
data_range() 함수를 이용하여 날짜를 생성/수정할 수도 있습니다.
시작할 기본 날짜를 지정하고 periods옵션을 이용해 며칠간의 데이터를 발생시킬 것인지 지정해 줄 수 있습니다.
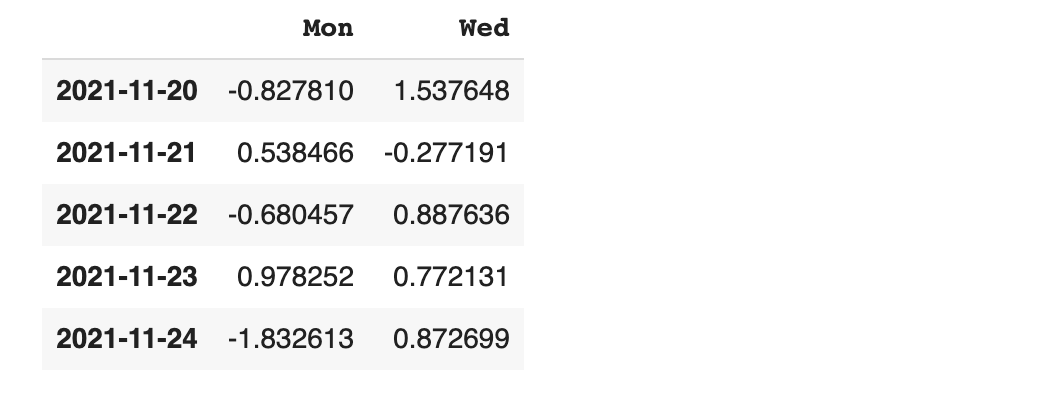
2021/11/20 를 기준으로 5일간 날짜 설정하기
Data Frame 직접 생성하기
데이터 프레임을 직접 생성할 때 필요한 여러 가지 옵션들에 대해 간단히 정리하겠습니다.
첫 번째 인자에는 데이터 프레임을 채울 데이터가 입력됩니다.
iterable 자료구조로 만들어 낼 수 있습니다.(member를 하나씩 차례로 반환 가능한 object - list, str, tuple...) index 옵션은 데이터 프레임의 인덱스로 지정할 값을 지정합니다. columns 옵션은 데이터 프레임에서 사용할 컬럼들이 list 형태로 지정됩니다.
index 란 데이터 프레임의 행마다 순서대로 붙어있는 구분자를 의미합니다.
head() 함수를 사용하여 원하는 데이터만 확인할 수 있습니다.
데이터 프레임의 정보 확인하기
index: 데이터 프레임의 인덱스 확인
columns: 데이터 프레임의 컬럼 확인
values: 데이터 프레임의 내부 값 확인하기
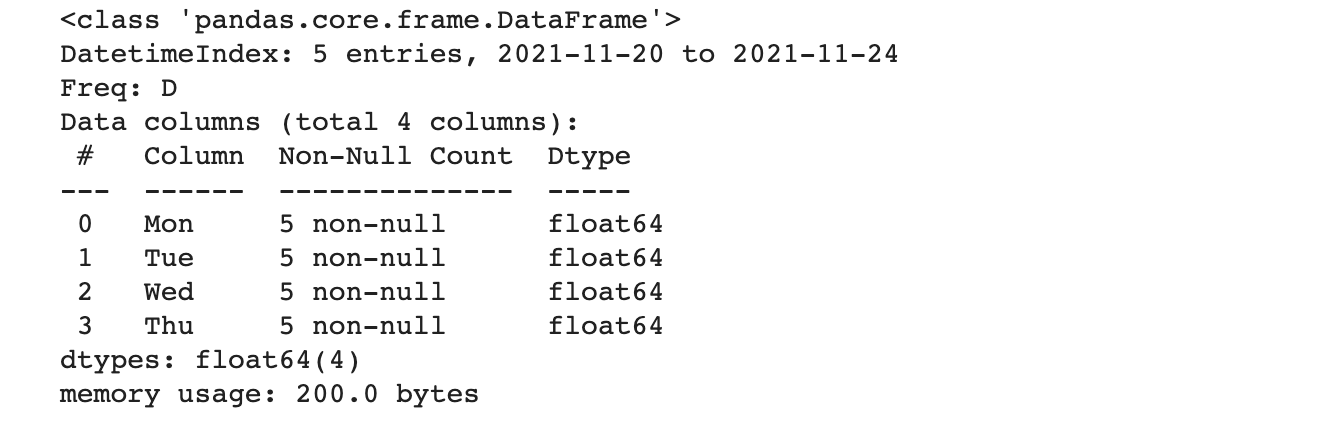
info(): 데이터 프레임의 간단한 개요 확인하기
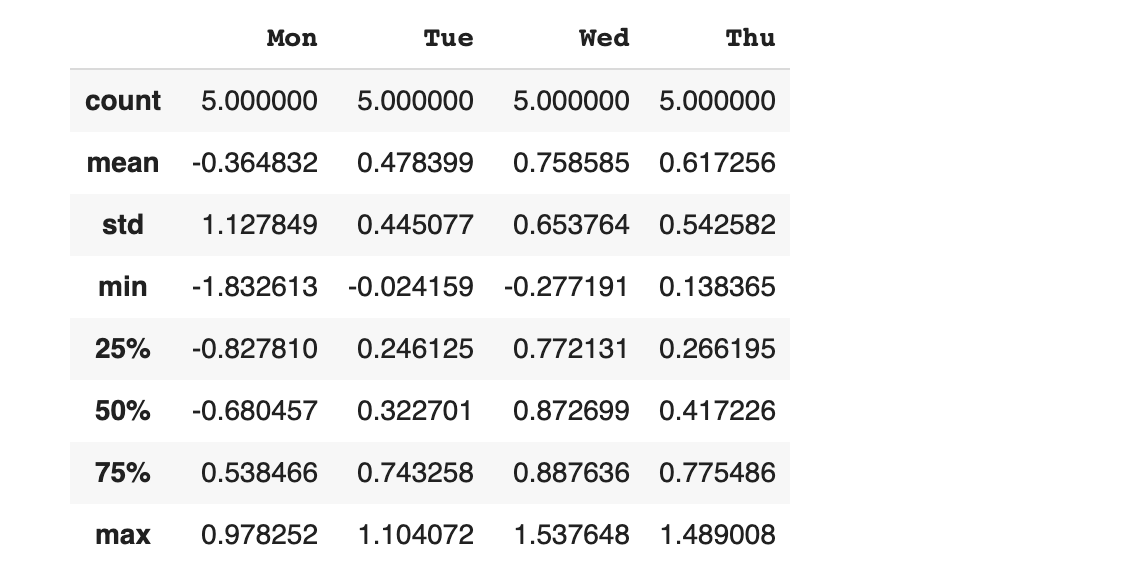
describe() : 통계적 개요 확인하기
데이터 개수 (count), 평균 (mean), 최솟값(min), 최댓값(max) 등
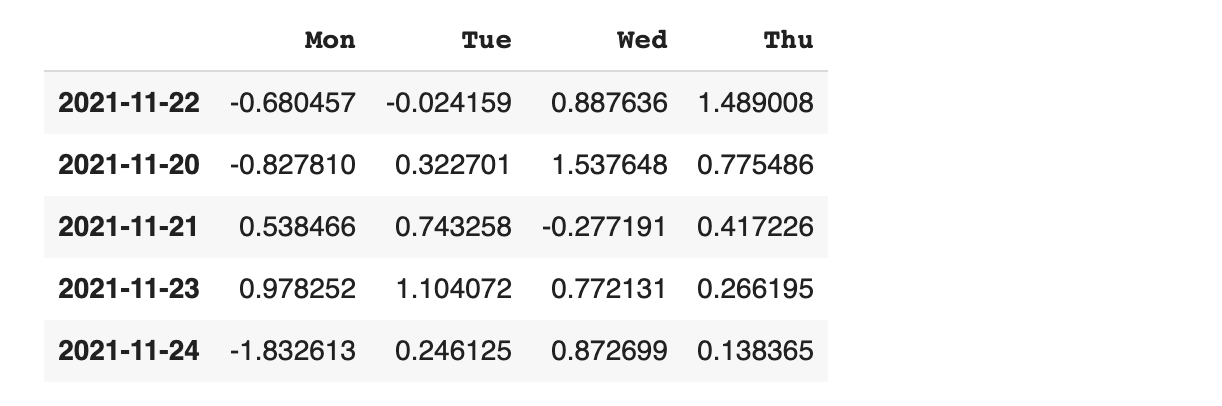
데이터 정렬(sort)
sort_values() 함수를 사용해 정렬을 할 수 있습니다.
이때 필요한 옵션은
by: 정렬 기준으로 삼을 컬럼을 지정 ascending: 내림차순(False), 오름차순(True) 지정
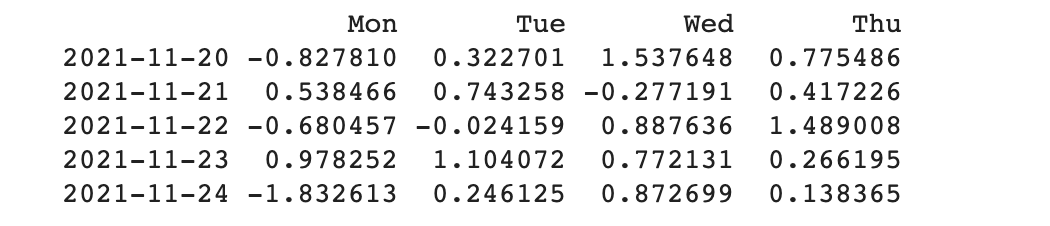
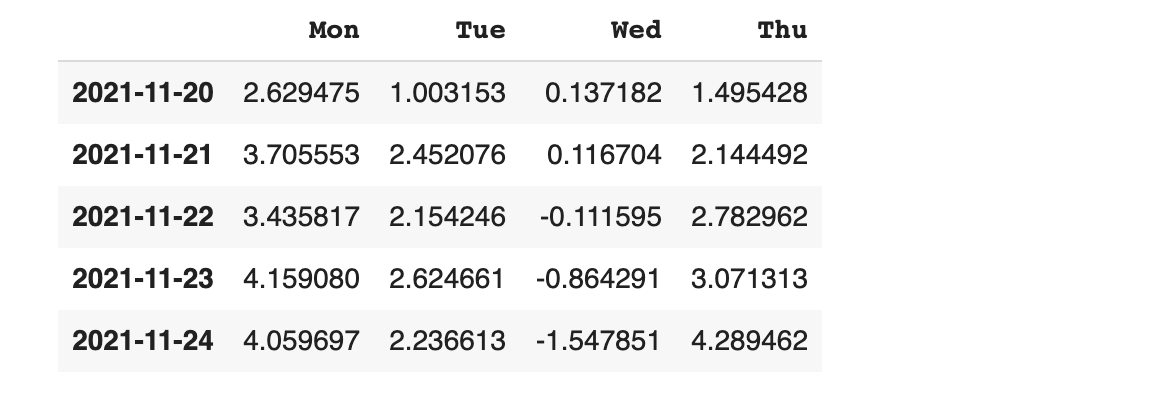
컬럼 Thu를 기준으로 데이터 프레임 정렬하기
데이터 선택 확인
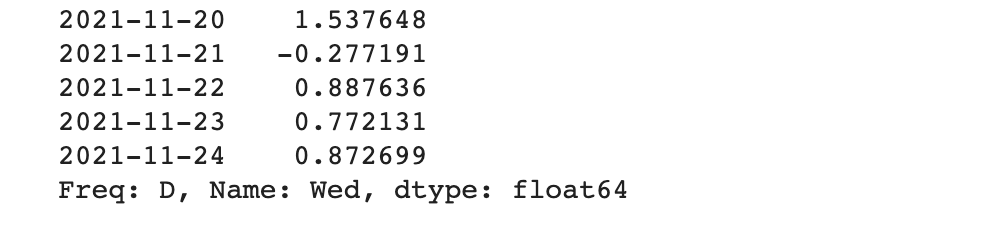
Data Frame에 원하는 컬럼 이름을 넣으면 Series 형태로 해당 컬럼의 데이터가 보입니다.
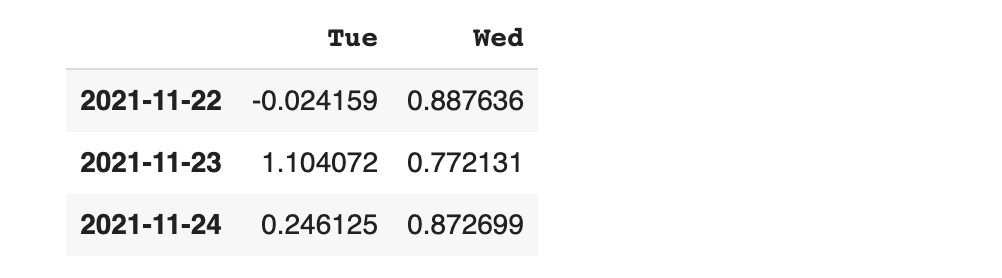
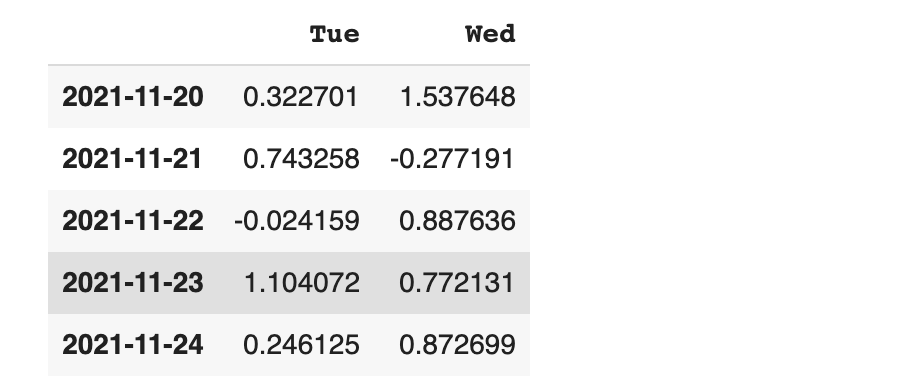
컬럼 Wed의 Series 확인하기
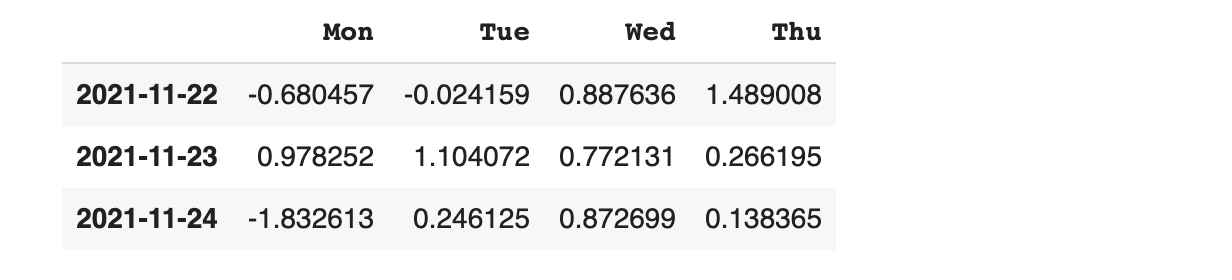
슬라이스 기법을 활용해서 출력 데이터 범위 지정하기
slice( [ start : end : step ] )을 데이터 프레임에 적용하면 원하는 범위의 데이터를 손쉽게 확인할 수 있습니다.
오프셋 0번부터 1번까지의 행 표시하기
오프셋이 아닌 인덱스의 이름으로도 슬라이스가 가능합니다.
특정 위치의 데이터 확인하기 loc
특정 위치(location)의 데이터만 확인하고 싶을 때는 loc 함수를 사용할 수 있습니다. loc 함수는 데이터 분석에서 정말 많이 이용되는 함수입니다. 첫 번째 인자는 행(row)을 뜻하고, 두 번째 인자는 열(column)을 뜻합니다.
dates 변수의 첫 번째 값을 활용해 해당하는 위치의 값 보기
직접 날짜를 지정해서 해당 날짜의 데이터를 확인하기
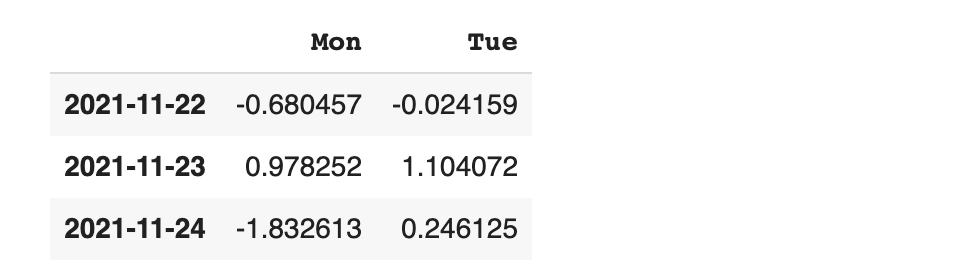
loc를 이용해 Mon, Wed 컬럼의 데이터들만 확인해 보겠습니다
이번에는 행에다가도 범위를 지정해 보겠습니다
물론 날짜를 직접 지정해 볼 수도 있습니다
또는, 인덱스를 생성할 때 정의했던 변수를 사용해 볼 수도 있습니다
dates[0]의 Mon, Tue 컬럼 확인. 컬럼을 리스트로 넣지 않으면 값만 확인 할 수 있습니다.
loc는 데이터의 값을 사용, iloc은 행과 열의 번호를 이용할 수 있습니다.
데이터 프레임이 가지고 있는 정확한 행, 열 이름을 정확히 모를 때는 번호(오프셋)를 사용해서 범위를 지정할 수 있습니다.
컬럼 선택을 다음과 같이도 할 수 있습니다.
데이터를 복사할 때는 copy() 함수를 사용
파이썬은 모두 객체죠?
할당과 복사를 다시 떠올려 보세요.
' = ' 만 사용하면 기존 객체가 변수에 할당됩니다. 따라서 copy() 메소드를 활용해 복사를 해야 합니다.
데이터 존재 유무 판단할 때는 isin 함수를 사용
현재 다루고 있는 데이터 프레임에 데이터가 존재하는지, 존재하지 않는지 True, False로 구분할 수 있습니다. 추후 데이터 분석 시에 조건으로써 활용될 수 있습니다.
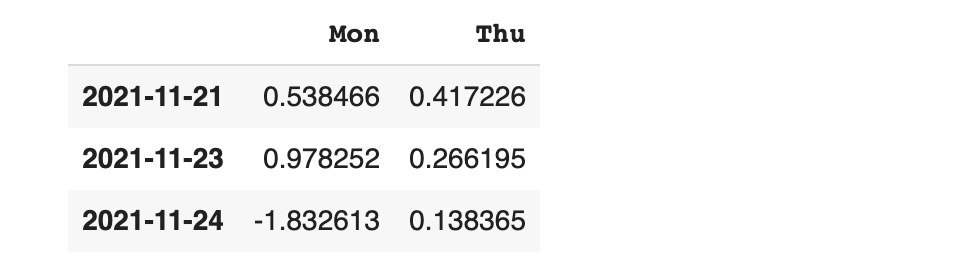
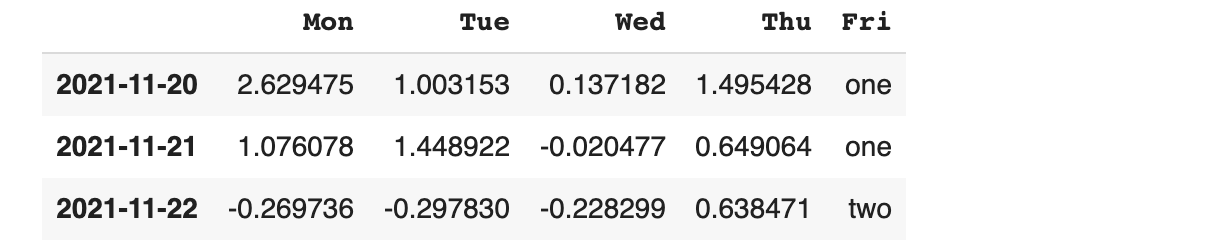
df2 에서 row별 two와 four가 존재 하는지 판단하기
isin을 조건으로써 활용하여 조건에 맞는 데이터만 가지고 와 보겠습니다
'Fri' column에 'one'과 'two'가 존재하는 row만 가져오기
데이터 프레임에서 간단한 통계 형태로 데이터를 확인할 때는 apply() 함수를 활용
numpy 모듈과 같이 사용하면 간단하게 여러 통계적 데이터를 확인할 수 있습니다.
꼭 numpy 모듈이 아니더라도 우리가 직접람다 함수를 만들어서 결과물을 확인 할 수도 있습니다.
최댓값 - 최솟값 ( 데이터들의 거리 ) 구하기
파이썬 데이터 분석을 위한 데이터 프레임을 pandas를 사용하여 간단하게 활용해보았습니다.
이번 포스팅에서는 Pandas를 활용한 파이썬에서 csv, excel 파일 읽어오는 방법에 대해서 알아보도록 하겠습니다.
pandas를 이용해 csv 파일을 불러오기 위해서는 아래와 같이 pandas를 먼저 import 해야 합니다.
pandas 모듈을 불러와서 pd 앨리어스를 붙여줍니다.
read_() 함수로 불러오기
엑셀 또는 csv파일을 읽어 올 때는 pandas 모듈의 read_csv나 read_excel 함수를 사용 하면 됩니다.
한글 데이터가 존재한다면 encoding-'utf-8'옵션으로 한글이 깨지지 않도록 신경 써 주어야 합니다.
제일 첫 행을 column이라고 합니다.
pandas를 이용해 불러온 데이터의 컬럼을 확인하기 위해 column을 사용할 수 있습니다.
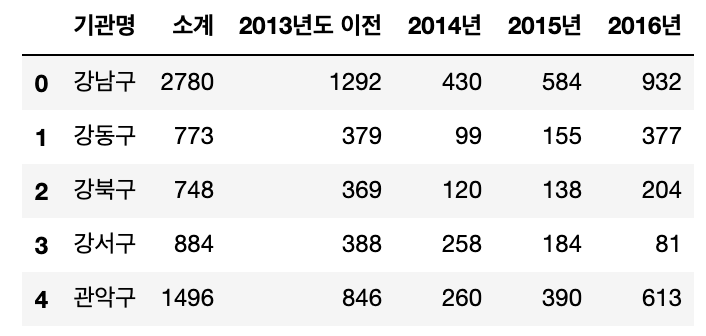
컬럼명 변경하기
위의 데이터 예제에서 컬럼명이 '기관명' 보다는 '구별' 로 변경하는 것이 더욱 구분하기 쉬운 명칭으로 보입니다. 이때, rename 함수를 사용해 컬럼의 명칭을 바꿀 수 있습니다. inplace = True옵션까지 설정하면 pandas로 읽어온 데이터의 컬럼명이 바뀌게 됩니다.
엑셀 파일 불러오기
CSV 파일을 읽어 온 것과 동일하게, 엑셀 파일은read_excel함수로 불러옵니다.
마찬가지로 한글이 들어있기 때문에 인코딩 옵션(encoding='utf-8')을 주겠습니다.
case 1 . 데이터의 내용이 좀 이상한 거 같아요...
첫 세줄의 모양새가 조금 이상합니다.
왜냐 하면 원본 엑셀 파일이 저렇게 되어 있기 때문입니다.
전처리가 필요한 이유 중에 가장 큰 이유가 여기서 나타납니다.
내가 원하는 데이터를 가진 파일이네? 불러오기만 하면 끝이다! BUT 모든 원본 데이터가 완벽하다고 생각하는 것은 큰 오산입니다.
값이 없거나, 중간중간 숫자가 아닌 한글이 들어가 있거나, 컬럼이 두줄로 존재하는 등 데이터를 다루기 쉽지 않은 파일들이 존재합니다.
그렇기 때문에 전처리과정이 중요하고 어떤 방식으로 해결하는지 알아보도록 합시다.
원하는 행(row)부터 데이터를 읽어 오기 위해서header옵션을 사용하고, 원하는 열(column)을 선택해서 읽어 오기 위해parse_cols를 사용합니다.
Data Frame column명 바꾸기
다시 한번 rename 함수를 이용해서 불러온 데이터의 컬럼명을 바꿔줍니다.
Pandas 를 이용하여 여러줄의 코드가 아닌, 손쉽게 데이터를 읽고, 편집할 수 있습니다.