이번 포스팅에서는 좀 더 편리하게 시각화하기 위해 Seaborn에 대하여 알아보도록 하겠습니다.
우선, Seaborn은 matplotlib을 기반으로 만들어져 통계 데이터 시각화에 최적화된 인기 라이브러리
Seaborn을 활용하면 시각화가 쉬워 집니다
사실 외울게 많습니다...ㅠㅠ
먼저 터미널이나 명령 프롬프트에서pip install seaborn을 입력하여 seaborn 모듈을 설치합니다.
Seaborn 은 좀 더 예쁘게 시각화할 수 있도록 도와줍니다.
간단한 비교를 위해 seaborn을 사용하지 않고 matplot만 사용하여 그래프를 그려 보겠습니다.

기초적인 시각화도 예쁘지만 이번엔 seaborn을 활용해서 여러 가지 스타일을 지정해 보겠습니다.
seaborn을 사용할 때 반드시 matplotlib 모듈도 같이 import 되어 있어야 합니다.

Seaborn에 있는 몇 가지 연습 데이터셋을 사용해 보도록 하겠습니다.
먼저 요일별 점심, 저녁, 흡연 여부와 식사 금액과 팁을 정리한 데이터입니다.


위 데이터는 단순히 요일별 매출을 시각화해본 그래프입니다.
이것만으로도 충분히 시각화가 쉬워지지만, hue라는 옵션을 이용하면 또 다른 데이터를 이용해서 데이터를 구분해 볼 수 있습니다.

위의 그래프를 확인해보면 흡연자가 더 결제범위가 큰 것이 확인됩니다
이번엔 약간 다른 스타일의 그래프를 그려 보겠습니다.
결제 금액과 종업원에게 주는 팁에 대한 회귀 분석 시각화입니다.
lmplot을 활용하면 간단하게 데이터 분석이 가능합니다.
적절한 상관계수를 확인할 때 사용하기 좋은 lmplot

회기 분석은 간단하게 말해서 예전에 그려봤던 상관계수라고 보시면 될 것 같습니다.
일전에 상관계수를 데이터와 데이터 사이에 상관 정도를 구해서 분석의 용도로 활용했는데, 회기 분석은 그 상관관계를 구하는 조금 더 정확한 방법이라고 보시면 될 것 같습니다.
즉, 위의 그래프에서 제시하는 결제금액에 따른 적절한 팁 액수를 확인할 수 있다는 것입니다.
결론적으로 "total_bill과 tip은 양의 상관관계를 갖는다"라고 이야기합니다.( total_bill이 많아질수록 tip이 많아지는 걸 알 수 있습니다)
또한 유효한 범위까지 그림으로 그려주는 것이 확인됩니다.
hue를 이용해서 흡연자로 비교해 보겠습니다.
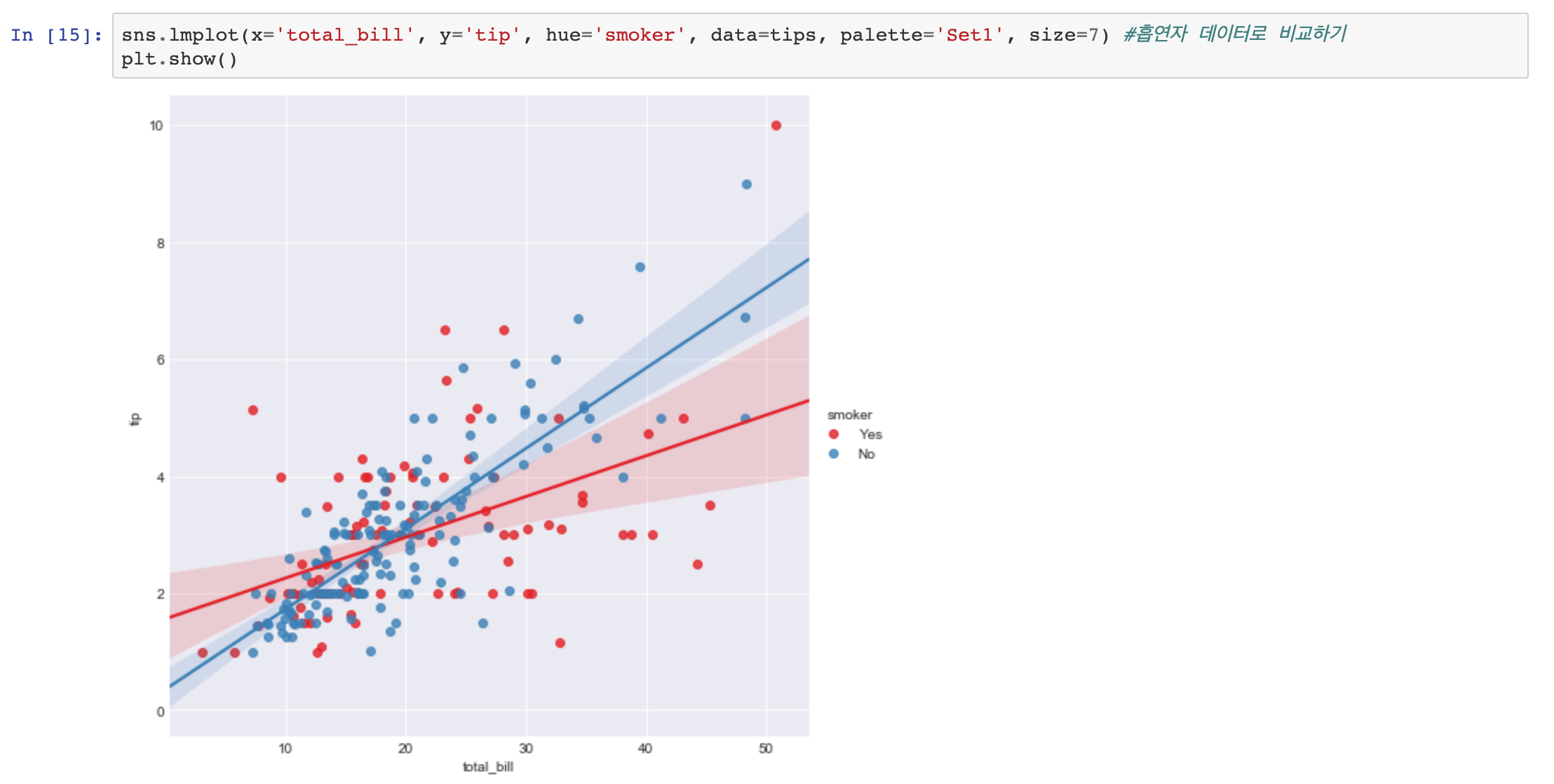
lmplot 시각화도 hue옵션을 가질 수 있고, palette 옵션을 이용해 색상도 지정해 주었습니다.
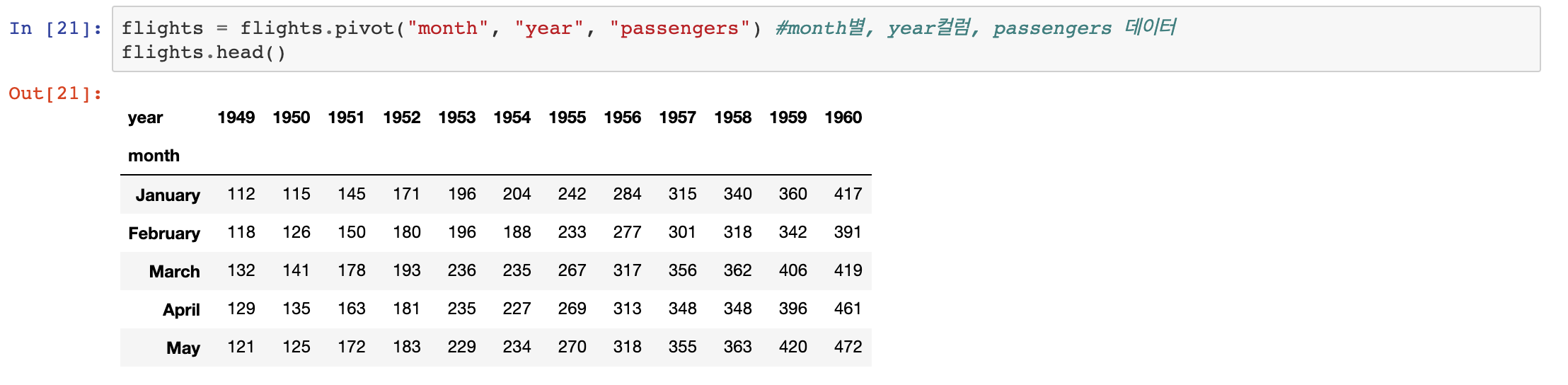
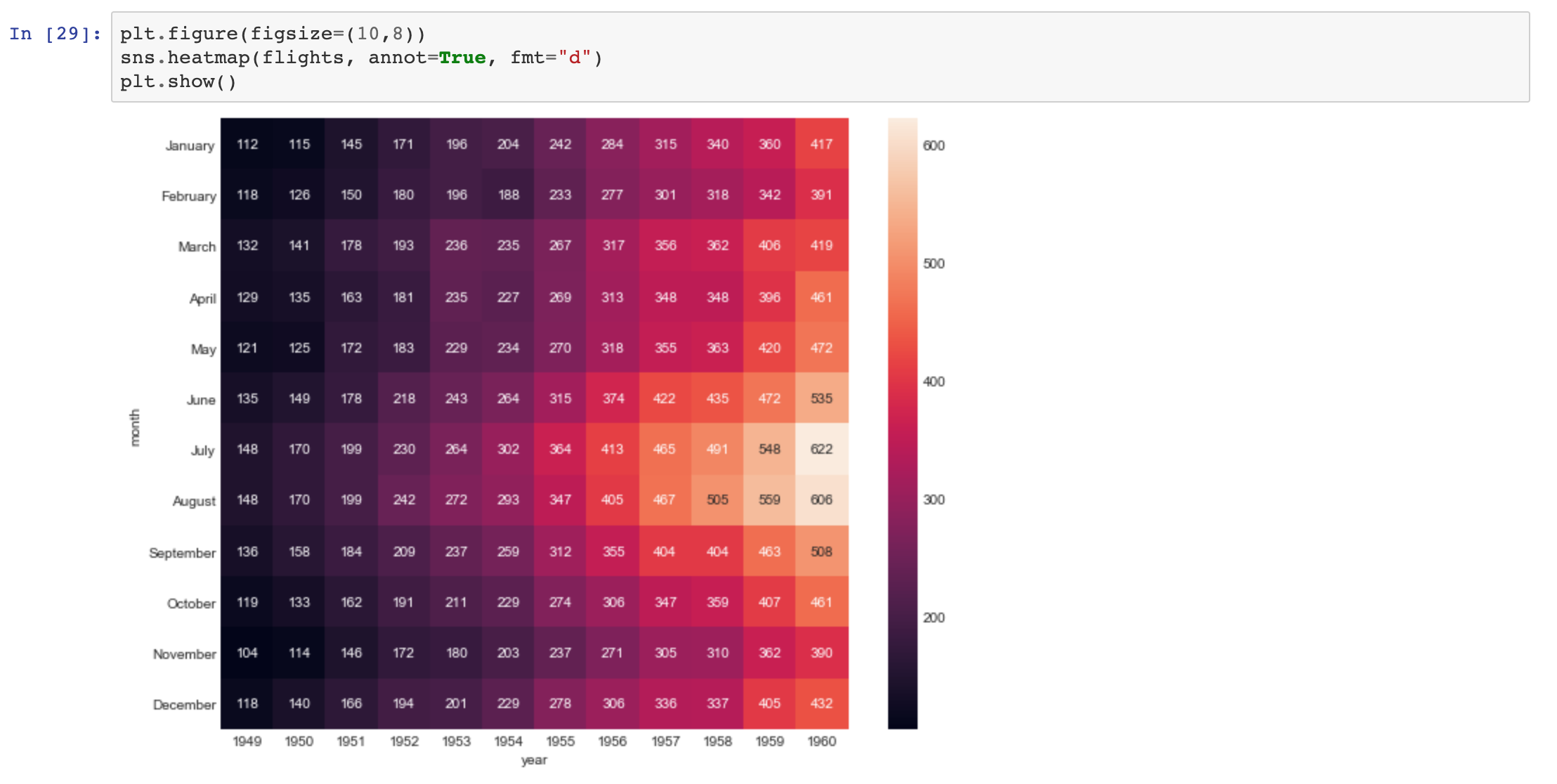
다음은 연도 및 월별 항공기 승객수를 기록한 데이터입니다

연도 및 월별 항공기 승객수로 구분하기 위해 pivot_table을 활용하겠습니다.
값 별 수치를 색상으로! heatmap을 사용하여 데이터 확인하기
heatmap을 활용하면 수치 별 시각화를 정말 쉽게 확인할 수 있습니다.
일전 데이터를 보고 pivot을 활용한다면 heatmap으로 데이터를 확인해보세요!
각 항목별 비교로 확인해 보기 pairplot
머신러닝에서 많이 사용되는 아이리스 꽃에 대한 데이터입니다. 각각의 데이터가 의미하는 바는 다음과 같습니다.
- Species : 붓꽃의 종. setosa, versicolor, virginica 세 가지 값 중 하나
- Sepal.Width : 꽃받침의 너비
- Sepal.Length : 꽃받침의 길이
- Petal.Width : 꽃잎의 너비
- Petal.Length : 꽃잎의 길이

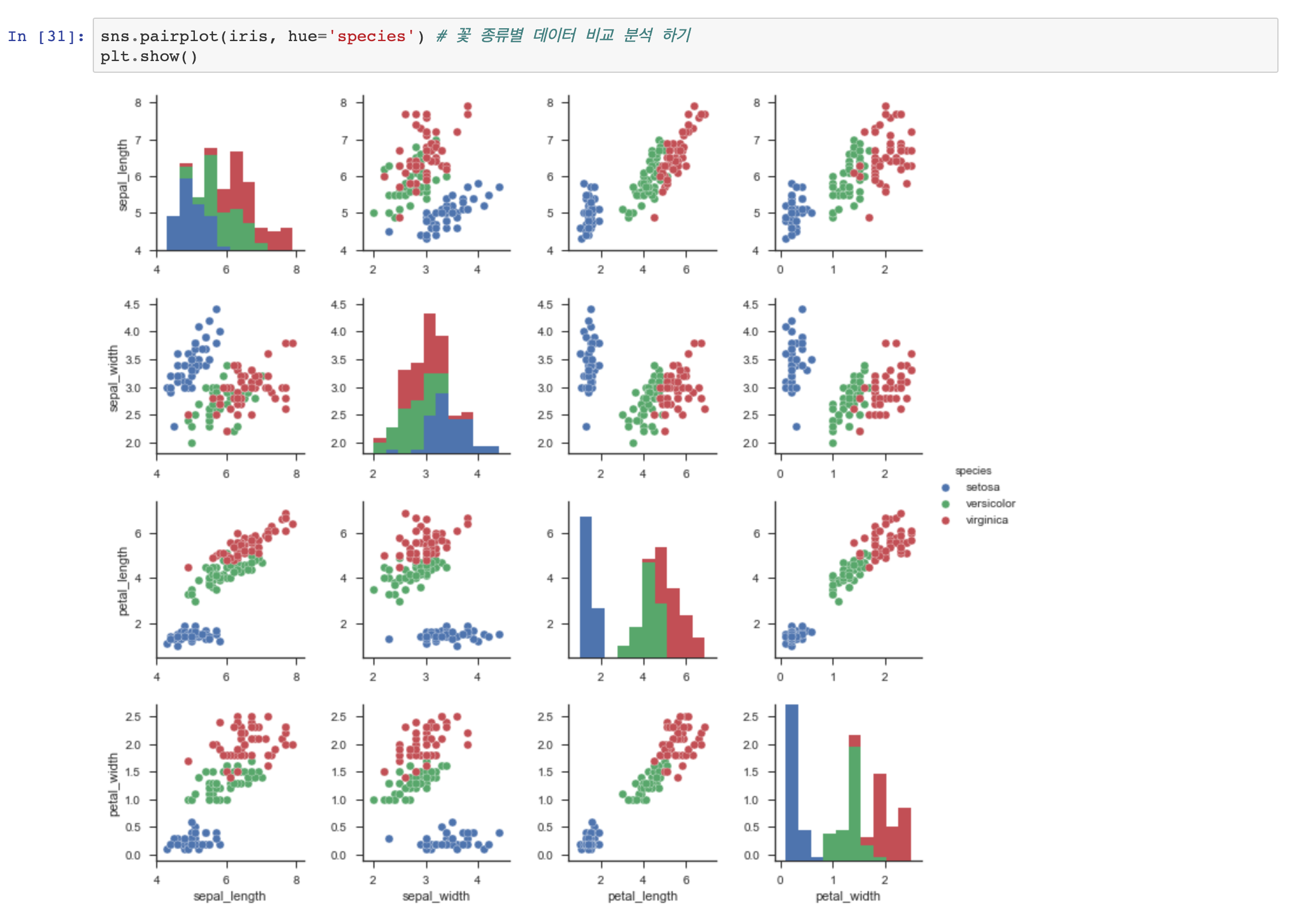
아주 간단하게 데이터 분석이 가능해집니다.
아이리스 예제는 인공지능 머신러닝에서 매우 중요하게 다뤄지는 예제입니다.
지금까지
다음 포스팅에서는 이전의 범죄 데이터를 활용하여 시각화 분석을 해보도록 하겠습니다.
'Programming > Python' 카테고리의 다른 글
| [Python] Matplotlib를 활용한 데이터 시각화 (0) | 2021.02.19 |
|---|---|
| [Python] 두개 이상의 데이터 프레임 병합 - concat 이용하기 (0) | 2021.02.18 |
| [Python] Pandas DataFrame #pandas 기초 .01 (DataFrame 생성, 정제 및 준비, 삭제, Data 내보내기) (1) | 2021.02.04 |
| [Python]Data Visualisation # 시각화 기초 (Plot, Bar) (1) | 2021.02.03 |