이번 포스팅에서는 붓꽃의 품종 분류를 통하여 지도학습에 대하여 알아보도록 하겠습니다.
사용 데이터는 scikit-learn 라이브러리에 있는 연습용 데모 데이터로써, 붓꽃의 품종을 꽃잎과 꽃받침의 크기에 따라서 분류해 놓은 데이터셋을 활용합니다.
가설 세우기
분석에 앞서 우리는 어떻게 데이터를 분석할지 가설을 세우는 것이 매우 중요합니다.
자, 여러분이 들판에서 붓꽃을 하나 발견했다고 가정합시다.
여러분들은 붓꽃에 대해서 잘 알지 못하기 때문에, 전문 식물학자가 측정한 데이터셋(우리가 활용할 데모 데이터셋)을 활용해야 합니다.
전문 식물학자가 측정해서 결과까지 내어 놓은 데이터셋은 데이터와 데이터에 따른 결과가 있을 것입니다.
붓꽃의 품종은 보통 setosa, versicolor, virgincia 이렇게 세 분류로 되어 있습니다.
예를 들어 꽃받침의 길이가 Xcm이고, 꽃잎의 길이가 Ycm 라면 virgincia라고 말한 것을 의미합니다.
문제 해결 하기
이러한 문제를 해결하기 위해서는 어떻게 해야 할까요?
여러분은 붓꽃의 품종 자체는 잘 알지 못하지만, 전문 식물학자가 작성해 놓은 데이터셋처럼 꽃받침, 꽃잎의 크기는 구할 수 있겠네요!
즉, 여러분이 채집한 붓꽃의 꽃받침, 꽃잎의 크기 ( 특성데이터 - feature )를 사용해 어떤 품종인지( 예측결과 - label )를 예측해야 합니다.
학습과 분류의 종류
여기서 우리가 사용할 데이터셋에는 품종을 정확하게 분류한 데이터를 가지고 있습니다. 따라서 지도 학습이라고 이야기할 수 있겠습니다.
몇 가지 선택사항( 품종 ) 중 하나를 선택해야 하는 문제입니다. 따라서 지금 예제는 분류(Classification)에 해당합니다.
여기서 출력될 수 있는 값들(여기서는 setosa, versicolor, virgincia)을 클래스(class)라고 합니다. 즉 측정한 데이터( feature )를 이용해 세 개의 클래스를 분류해야 한다고 볼 수 있겠습니다.
붓꽃 하나에 대한 기대 출력은 그 꽃의 품종이 됩니다. 이런 특정 데이터 포인트에 대해 기대할 수 있는 출력( 여러분이 채집한 꽃에 대한 품종 )을 레이블( label )이라고 합니다.
데이터를 통하여 한번 알아보도록 하겠습니다!
데이터 적재하기
scikit-learn의 datasets 모듈에 있는 iris 데이터를 불러와 봅시다.
from sklearn.datasets import load_iris
iris_dataset = load_iris() # python의 dict 클래스와 유사한 Bunch 클래스의 객체
# print(iris_dataset)<- 출력이 되는지 확인하기
print('iris_dataset의 키 : \n{}'.format(iris_dataset.keys())) # iris 데이터셋의 키 확인하기
# iris 데이터셋의 DESCR 키에는 간략한 설명이 들어있습니다.
print(iris_dataset['DESCR'][:193], "\n...")
# target_names 키는 우리가 예측할 붓꽃 품종의 이름을 문자열 배열로 가지고 있습니다.
print("타깃의 이름 : {}".format(iris_dataset['target_names']))
# feature_names 키는 각 특성을 설명하는 문자열 리스트 입니다.
print('특성의 이름 : {}'.format(iris_dataset['feature_names']))
# 실제 데이터는 target과 data 필드에 들어 있습니다.
# data는 feature 로써, 꽃받침과 꽃잎의 길이의 값이 들어 있습니다.
print('data의 타입 : {}'.format(type(iris_dataset['data'])))
# data 배열의 행은 각각 꽃에 대한 데이터입니다. 즉 4개의 측정치(꽃받침의 너비와 길이, 꽃잎의 너비와 길이)
print('data의 크기 : {}'.format(iris_dataset['data'].shape))
# data 배열의 실제 데이터를 확인 합니다. 5개의 데이터만 확인 해봅니다.
print('data의 처음 다섯 행 :\n{}'.format(iris_dataset['data'][:5]))
# target 배열은 붓꽃의 품종이 담겨 있습니다.
print('target의 타입 : {}'.format(type(iris_dataset['target'])))
print('target의 크기 : {}'.format(iris_dataset['target'].shape))
# 붓꽃의 종류는 0, 1, 2 형태의 정수로 들어 있습니다.
print('target:\n{}'.format(iris_dataset['target'])) # iris['target_names']에서 숫자의 의미를 파악 할 수 있습니다.
print('target mean : {}'.format(iris_dataset['target_names'])) # 0은 setosa, 1은 versicolor, 2는 virgincia 입니다.
신뢰할 수 있는 모델과 예측인지 확인하기
위의 데이터를 토대로 머신러닝 모델을 만들어서 위에 데이터셋에는 없는 새로운 데이터를 이용해 적용하기 전에 모델이 잘 작동하는지 검증하는 작업을 해봐야 합니다. 즉, 위의 iris_dataset이 신뢰할 수 있는 데이터 인지를 확인해봐야 하겠죠.
그렇다면 위의 데이터는 평가의 목적으로 사용할 수 있을까요? 애석하지만 위의 데이터는 평가용이 아닌 학습용도로 만들어 놓은 데이터 이기 때문에 iris_datasets의 데이터는 새로운 데이터로써 사용할 수 없는 상태입니다. 즉, 이미 위의 iris_datasets는 훈련에 의해 컴퓨터가 이미 다 알고 있는 데이터 이기 때문에 모든 데이터를 정확하게 맞출 수 있기 때문이죠. 이처럼 이미 컴퓨터가 데이터를 기억한다는 것은 모델의 일반화가 잘 이루어져 있지 않았다( 새로운 데이터에 대해서는 잘 작동하지 않는다)라고 이야기합니다.
모델의 성능을 측정하기 위해서는( 정확도를 구하기 위해서는 ) 새로운 데이터가 필요합니다. 새로운 데이터를 당장에 만들어 내는 것은 조금은 번거롭고 어려운 작업입니다.
측정을 잘할 수 있는 성능테스트 하기
자, 우리가 만들 모델을 측정하기 위해 가장 간단한 방법은 무엇일까요? 바로 위의 데이터셋을 두 그룹으로 적절하게 나누는 것입니다.
- 첫 번째 세트는 머신러닝 모델을 만들 때 사용 합니다. 이를 훈련 데이터 또는 훈련 세트라고 합니다.
- 두 번째 세트는 첫 번째 세트로 만들어낸 머신러닝 모델의 테스트 용도로써 사용합니다. 이를 테스트 데이터, 테스트 세트 또는 홀드아웃 세트라고 합니다.
scikit-learn은 데이터셋을 적절하게 섞어서 나눠주는 train_test_split 함수를 제공하고 있습니다.
이 함수의 역할은 전체 행 중 75%가량을 레이블 데이터( feature에 의해 맞춰야 할 결과 값)와 함께 훈련용 데이터( feature )로 뽑습니다.
나머지 25% 정도의 데이터셋은 테스트 세트가 됩니다. 물론 상황에 따라 조절할 수 있습니다. ( test_size 매개변수 활용 )
훈련용 데이터와 테스트 데이터 나눠내기
scikit-learn에서 데이터는 X로 표기하고, 레이블은 y로 표기합니다. 수학의 f(x) = y에서 유래하였습니다.
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(iris_dataset['data'], iris_dataset['target'], random_state = 0)
print('X_train의 크기 : {}'.format(X_train.shape))
print('y_train의 크기 : {}'.format(y_train.shape))
train_test_split을 활용하여 데이터를 나눌 때는 랜덤 하게 나눠져야 합니다. iris_dataset ['target']을 이용해 확인해봤지만, 맨 뒤에 있는 데이터는 전부다 레이블이 2로 동일합니다.
세 클래스 중 하나만 포함한 테스트 세트를 사용하면 일반화가 잘 이루어지지 않겠죠. 따라서 테스트 세트를 적절하게 잘 섞어줄 수 있도록 난수(random)를 활용합니다.
기본적으로 train_test_split 함수에서 랜덤으로 셔플링(shuffle)을 해주지만, 실행할 때마다 실행 결과가 달라질 수 있기 때문에 seed의 개념을 이용해 랜덤값을 고정시킬 수 있습니다.( random_state = 0 또는 아무거나 들어가도 됩니다!)
print('X_test 크기 : {}'.format(X_test.shape))
print('y_test 크기 : {}'.format(y_test.shape))
데이터 시각화로 살펴보기
train_test_split과 같은 메소드를 이용해서 훈련용(X_train, y_train) 데이터와 테스트용(X_test, y_test) 데이터를 나눠 보았습니다.
실제 훈련과 테스트를 해보기 이전에 신뢰할 수 있는 데이터 인지 시각화를 통해 살펴보겠습니다.
이를 통해 우리는 비정상적인 값이나 특이한 값들을 눈으로 확인해 볼 수 있을 것입니다. pandas 도표 또는 jupyter notebook에서 문자로 보는 것보다 도표를 이용해 보는 것 이기 때문에 한눈에 보기도 쉽고 간편할 것입니다.
어떻게 시각화를 할까?
여러 종류의 데이터가 분포되어 있고, 여기에 대해서 결과물이 나오고 있는 형태입니다. 이때 우리가 생각해 볼 수 있는 내용은 산점도(Scatter plot)를 활용한 방법이 좋습니다.
한 특성을 x축에 놓고, 다른 하나는 y축에 놓아 각 데이터 포인트를 하나의 점으로 나타내는 그래프입니다. 하지만 우리가 사용하고 있는 특성은 총 4가지(꽃받침, 꽃잎의 가로세로) 이기 때문에 하나의 그래프에 확인하기가 힘듭니다. 따라서 산점도 행렬(Scatter matrix)을 이용해 확인해 보도록 하겠습니다.
먼저 그래프를 그리기 전에 numpy로 만들어 놓은 배열을 Pandas의 DataFrame으로 변경해야 합니다.
import matplotlib.pyplot as plt
import pandas as pd # pandas 모듈 임포트하기
import mglearn
%matplotlib inline
# 훈련용 데이터인 X_train 데이터를 이용해 데이터 프레임을 만들어 줍니다.
# y축이 될 열의 이름은 iris_datase.feature_names에 있는 문자열을 사용하겠습니다.
iris_dataframe = pd.DataFrame(X_train, columns=iris_dataset.feature_names)
pd.plotting.scatter_matrix(iris_dataframe, c=y_train, figsize = (15, 15), marker='o',
hist_kwds={'bins':20}, s = 60, alpha = .8, cmap=mglearn.cm3)
plt.show()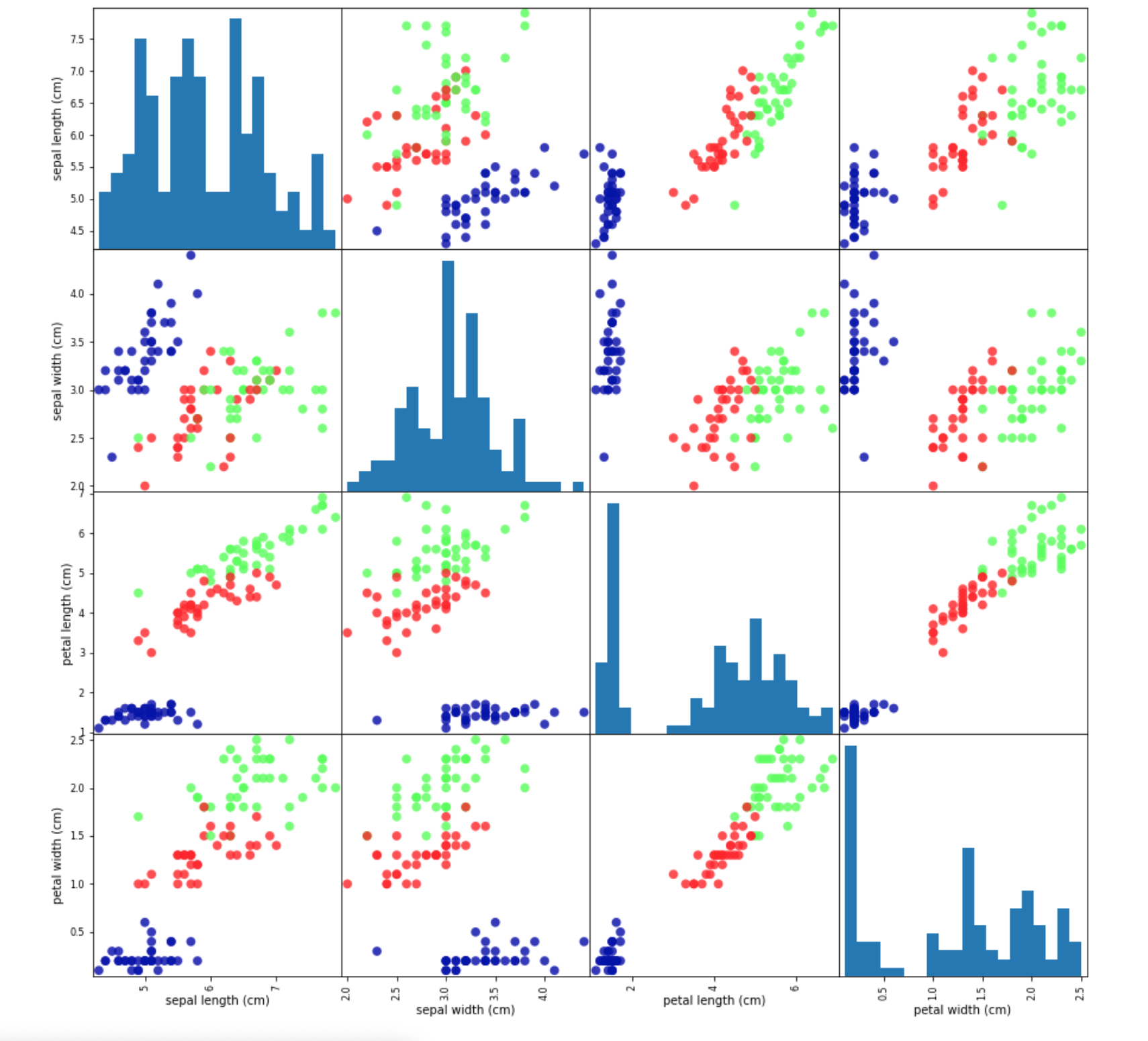
k-최근접 이웃 알고리즘
k-NN( k-Nearest Neighbors - k-최근접 이웃 ) 알고리즘은 새로운 데이터에 대한 예측이 필요할 때 새로운 데이터와 가장 가까운 k개의 훈련된 데이터 포인트들을 찾아냅니다.
즉 k는 하나의 이웃이 아닌 복수의 이웃이라는 것이죠.
이 이웃들의 클래스 중에서 빈도가 가장 높은 클래스를 예측값으로 사용하게 됩니다.
덧붙여서 scikit-learn의 머신러닝 모델은 BaseEstimator라는 파이썬 클래스를 상속받아 구현되어 있습니다.
KNeighborsClassifier 클래스를 사용할 텐데, 이때 n_neighbors 매개변수는 이웃의 개수를 지정해 줍니다.
일단 가장 가까운 이웃만 하나 골라내기 위해서 n_neighbors를 1로 지정하겠습니다.
from sklearn.neighbors import KNeighborsClassifier #KNN 분류기
knn = KNeighborsClassifier(n_neighbors=1) # 이웃의 갯수를 1개로 강제 지정위에서 만든 knn 객체는 훈련 데이터로 모델을 만들고 새로운 데이터 포인트에 대해 예측하는 알고리즘을 캡슐화하였습니다.
또한 알고리즘이 훈련 데이터로부터 추출한 정보까지 담아내고 있습니다. KNeighborsClassifier의 경우는 훈련 데이터 자체를 저장하고 있습니다.
훈련시키기 Fit
fit 메소드를 활용하면 드디어 모델을 만들어 낼 수 있습니다.
이때 훈련해야 할 데이터는 위에서 만들어 놓은 X_train과 y_train이 되어야겠죠?
knn.fit(X_train, y_train)
fit 메소드를 활용하면 머신러닝 알고리즘 객체 자체가 반환이 됩니다.
knn 객체를 생성할 때 n_neighbors 매개변수를 1로 설정하였는데, 결과를 보니 잘 된 것 같습니다.
매개변수의 종류가 상당히 많은데, 다음 포스트에서 바로 다뤄 보도록 하겠습니다!
데이터 신뢰도를 위한 예측
시각화를 통해 신뢰할 수 있는 데이터 인지 (각 데이터에 따라서 붓꽃의 종류가 잘 구분되었는지) 알아보았고, 알맞은 데이터라는 판단이 들어서 fit 메소드를 사용해 모델을 만들어 냈습니다.
이제 본격적으로 예측을 해볼 텐데요, 먼저 여러분이 수집한 붓꽃에 대한 데이터를 임의로 지정해 보도록 하겠습니다.
X_new 객체는 여러분이 수집한 붓꽃의 데이터가 들어있는 Numpy 배열입니다.
import numpy as np
X_new = np.array([[5,2.9,1,0.2]])
print("X_new.shape : {}".format(X_new.shape))
데이터가 잘 준비되었으면 이제 예측해 봅시다. 예측할 때는 predict 메소드를 사용합니다.
prediction = knn.predict(X_new) # 예측할 데이터인 X_new의 결과를 prediction으로 저장
print("예측: {}".format(prediction))
print("예측한 타깃의 이름: {}".format(iris_dataset['target_names'][prediction]))
잘 작동은 한 것 같습니다. 하지만 이 결과를 과연 신뢰할 수 있나요? 이때 필요한 것이 모델을 평가하는 것입니다.
앞서 X_train, y_train 말고도 X_test, y_test 데이터셋을 따로 만들어어 놓았습니다. 총데이터셋의 크기 중 25% 정도를 차지하는 이 데이터 셋들은 테스트, 즉 평가의 용도로 사용하게 됩니다.
여기에는 4가지 데이터와 정답이라고 할 수 있는 붓꽃의 품종까지 들어 있습니다. 우리는 이제 훈련한 머신러닝 모델과 정답이 들어있는 테스트 데이터를 이용해 예측하고, 얼마만큼 우리가 만든 모델이 붓꽃의 품종을 맞췄는지 알아볼 수 있습니다.
즉, 정확도를 계산하여 모델의 성능을 평가해 낼 수 있습니다.
y_pred = knn.predict(X_test) # 테스트 데이터셋을 넣어서 예측 하기
print("테스트 세트에 대한 예측값:\n {}".format(y_pred))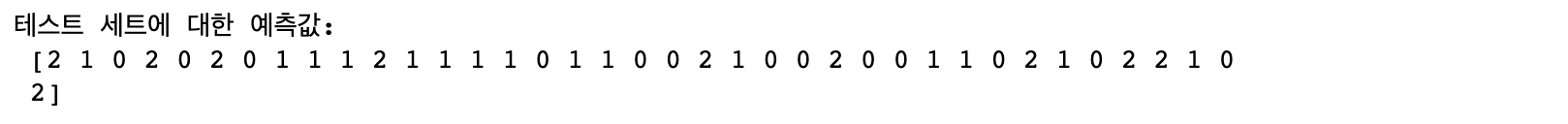
print('테스트 세트의 정확도: {:.2f}'.format(np.mean(y_pred == y_test))) # 정답이 들어있는 y_test와 knn 모델이 에측한 y_pred의 일치도
97퍼센트의 정답률이 나왔습니다. 꽤나 정확하게 붓꽃들을 구분했다고 볼 수 있습니다. 보통 정확도는 70% 이상이면 적합한 성능에 포함합니다. 물론, 높으면 높을수록 분석에 높은 확률을 주는 건 당연한 이야기겠죠~
앞으로 우리는 이렇게 신뢰할 수 있는 머신러닝 모델을 만들기 위해 성능을 높이는 방법과 모델을 튜닝할 때 주의할 점들을 알아봐야 합니다.
'Programming > 특성 공학' 카테고리의 다른 글
| [Machine Learning] 최근접 이웃(K-NN) (0) | 2023.04.24 |
|---|---|
| [Machine Learning]지도 학습의 종류 (0) | 2023.04.18 |
| [데이터 전처리]수치 변환 (1) | 2023.04.04 |
| [Machine Learning]일변량 통계 (0) | 2023.03.28 |
| [데이터 전처리]구간분할과 이산화 & 상호작용과 다항식 (0) | 2023.03.21 |