728x90
반응형
SMALL
이번 포스팅에서는 딥러닝에서 필연적으로 마주하게 되는 기본 Numpy에 대하여 알아보도록 하겠습니다.
numpy는 내부적으로 C로 구현이 되어 있으며, 수치에 관련된 프로그래밍을 할 때 일반 python보다 훨씬 빠릅니다.
특히, 배열 연산에 특화되어 있습니다.
한번 예제를 통하여 바로 알아보도록 하겠습니다!
import numpy as np
# 일반 파이썬 리스트를 numpy 배열화 ( numpy 배열 : ndarray )
py_list = [1, 2, 3]
arr1 = np.array(py_list)
arr1
# ndarray 타입 확인하기
type(arr1)
py_list = [ [1, 2, 3],
[4, 5, 6] ]
arr2 = np.array(py_list)
type(arr2)
numpy에서는 숫자 배열을 만들기 위한 여러 가지 함수를 제공합니다.
np.arrange()
# np.arange 함수는 파이썬의 range 함수와 매우 흡사하다.
arr = np.arange(10) # 0 ~ 9 까지 들어있는 숫자 배열을 생성
arr
arr = np.arange(1, 10) # 1 ~ 9 까지 들어있는 숫자 배열을 생성
arr
arr = np.arange(1, 10, 2) # 1부터 9까지 2씩 띄워가면서 숫자 배열 생성
arr
다차원 배열 만들기
- np.zeros
- np.ones
- np.full
np.zeros: 지정한 차원에 모든 원소를 0으로 채워주는 함수
np.zeros(5) # 1차원 배열에 5개의 0을 채운다.
np.zeros((4, 5)) # 4행 5열(2차원 배열)의 배열에 0을 채운다.
np.zeros((3, 4, 5))
np.ones: 지원한 차원에 모든 원소를 1로 채워주는 함수
np.ones(5)
np.ones((4,5))
np.ones((4, 5)) * 3
np.full: 지정한 차원에 모든 원소를 원하는 수로 채우는 함수
np.full((3,4),7)
단위행렬 만들기
- np.eye
- 단위 행렬 : 대각선 방향의 원소가 1이고, 나머지 원소는 0인 행렬
np.eye(3)
np.eye(3, 4)
구간 나누기
- np.linspace
np.linspace(1, 10, 3) # 1부터 10까지 2개의 구간 만들기
np.linspace(1, 10, 4)
Random을 사용하기 위한 numpy
- 보통 랜덤한 배열은 딥러닝에서 매개변수의 초기화를 하기 위해 사용
- 딥러닝에서는 일반적으로 Xavier 초깃값, He 초깃값, 정규분포 초깃값을 계산해 준다.
np.random.rand: 완전한 랜덤 만들기 (정규분포나 균등분포가 아닌 랜덤값)
np.random.randn(10)
np.random.uniform: 균등분포 랜덤값 만들기
np.random.uniform(1.0, 3.0, size=(4, 5)) # 1.0 ~ 3.0 까지 균등분포 랜덤값 생성
정수 랜덤 만들기
np.random.randint
np.random.randint(1, 100, size=(5, )) # 1차원 배열의 원소 5개에 1 ~ 100까지의 랜덤값으로 채우기
np.random.randint(1, 100, size=(5, 1)) # 2차원 배열에 랜덤 정수 채우기
np.random.randint(1, 100, size=(3, 4, 5))
정수 랜덤 샘플링 하기
np.random.choice
- 랜덤 샘플링 : 일정한 범위 내에서 필요한 정수를 랜덤으로 추출
- 미니배치를 만들 때 사용
np.random.choice(100, size=(3, 4))
# 임의의 배열을 만들어서 그 안에서 랜덤하게 추출할 수 있도록 함
arr = np.arange(1, 6)
np.random.choice(arr, size=(2, 2), replace=False) # replace가 True면 원소를 중복 추출, False면 중복 추출 X
인덱스와 슬라이싱
arr = np.arange(1, 11).reshape(2, 5)
arr
arr[:, 2] # 2차원 배열 내에서 1차원 배열은 전체 선택, 0차원 스칼라값은 2번째 인덱스에 있는 것을 선택
arr = np.arange(1, 37).reshape(3, 4, 3)
arr
arr[:, :2, :2]
배열의 차원과 형상
- 형상( shape )
- 차원수( ndim )
arr = np.arange(12).reshape(3, 4)
arr
arr.shape
arr.ndim
차원수 확장하기
- 항상 같은 예시는 아니지만, 보통은 이미지 분석( CNN )을 하기 위해 데이터를 전처리 하면서 사용된다.
- tensor flow는 tf.newaxis를 활용, numpy는 np.newaxis를 활용해서 추가 차원을 만들어 낼 수 있다.
arr
arr.shape
tmp_arr = arr[np.newaxis, :, :, np.newaxis] # arr의 첫 번째와 마지막에 차원을 1씩 확장
tmp_arr
# 실제 데이터를 다룰 때는 실제 데이터를 보는 것이 아닌, shape만 보자..
tmp_arr.shape
# 각 차원이 1인 차원 삭제하기
tmp_arr2 = np.squeeze(tmp_arr)
tmp_arr2.shape
spread 연산자 활용하기
- 슬라이싱 도중에 특정 차원부터는 전체를 선택할 때 사용한다.
tmp_arr3 = arr[np.newaxis, ..., np.newaxis] # ... -> spread 연산자
tmp_arr3.shape
배열의 형상 (shape) 바꾸기
- np.newaxis를 활용해서 축을 추가한다. ( 차원수를 늘린다. )
평탄화
- ravel : 원본 배열을 평탄화시킨참조배열을 만들어 낸다. ( View 또는 Reference를 만들었다고 표현한다. )
- flatten : 평탄화시킨 복사된배열을 만들어 낸다.
형상 변환
- reshape
ravel 사용하기
x = np.arange(15).reshape(3, 5)
x.shape
print("원본 x : \n{}".format(x))
temp = np.ravel(x)
print("ravel로 평탄화된 x의 shape : {}".format(x.shape))
print("ravel로 평탄화된 x : \n{}".format(temp))
ravel함수는 원본의 참조본을 만들어 낸다.
print(temp[0])
temp[0] = 100
print(x)
flatten 사용하기
# flatten은 복사본을 만들어 낸다.
y = np.arange(15).reshape(3, 5)
temp2 = y.flatten()
print("원본 y : \n{}".format(y))
print("flatten으로 평탄화된 y의 shape : {}".format(temp2.shape))
print("flatten으로 평탄화된 y : \n{}".format(temp2))
temp2[0] = 100 # flatten을 활용해서 y의 복사본을 만들어 냈기 때문에 원본 y에는 영향을 미치지 않는다.
print(temp2)
print(y)
reshape 사용하기
x = np.arange(20)
x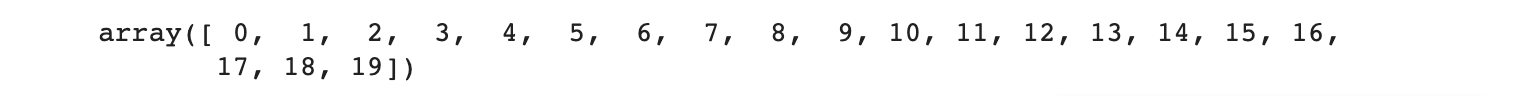
reshape 팁 : reshape 함수 내의 모든 숫자를 곱했을 때 스칼라 원소의 개수와 같기만 하면 된다.
x.reshape(2, 5, 2)
-1을 reshape()에 넣으면 남는 숫자를 자동으로 계산해 준다.
x.reshape(2, 2, -1) # 2 * 2 는 4니까, -1은 5를 의미하게 된다.
x.reshape(2, -1, 2)
x.reshape(3, -1) # 오류... 한쪽 차원의 수가 3이면 원소의 개수인 20만큼 딱 떨어지지 않기 때문에 오류
브로드 캐스팅
- 차원 수가 다른 배열끼리의 연산
- 차원이 달라도 0차원 스칼라의 개수가 똑같으면 연산이 가능
- 저 차원의 배열을 고차원으로 확장
x = np.arange(20).reshape(4, 5)
y = np.arange(20, 40).reshape(4, 5)
print(x)
print()
print(y)
x.shape, y.shape
x + y
x - y
x * y
원소의 개수와 차원이 같으면 자연스럽게 원소끼리 연산을 할 수 있다.
x * 2
x는 2차원, 2는 0차원 스칼라 값이다. 2의 차원이 곱해지는 배열인 x의 shape으로 확장된다.
# shape이 다를 때의 연산
a = np.arange(12).reshape(4, 3) # ( 4, 3 )
b = np.arange(100, 103) # (3, )
c = np.arange(1000, 1004) # (4, )
d = b.reshape(1, 3) # (1, 3)
# b와 d의 다른점 : b는 1차원, d는 2차원a + b
a + c
a + d
전치행렬 만들기
- 행렬 A의 행과 열의 인덱스를 바꾼 것을 전치행렬이라고 한다.
- 𝐴(𝑖,𝑗)의 위치를 𝐴(𝑗,𝑖)로 바꾼 것
- 보통 Transpose 했다고 이야기한다.
e = np.arange(6).reshape(2, 3)
e
# ndarray에서 T만 호출해 주면 된다.
e.T
특히 역전파에 사용된다!
지금까지 파이썬을 활용하여 딥러닝을 위한 numpy의 기초를 총 정리 해보았습니다.
다음 블로그에서는 퍼셉트론에 관하여 알아보도록 하겠습니다.
728x90
반응형
LIST
'Programming > Deep Learning' 카테고리의 다른 글
| [Python/DeepLearning] #6. 출력층(output layer) 설계 (1) | 2023.10.11 |
|---|---|
| [Python/DeepLearning] #5. 행렬과 신경망 (0) | 2023.08.30 |
| [Python/DeepLearning] #4. 다차원 배열의 계산 (0) | 2023.08.23 |
| [Python/DeepLearning] #3. 활성화 함수의 기본 (0) | 2023.08.18 |
| [Python/DeepLearning] #2. 퍼셉트론 (단층 & 다층) (0) | 2023.08.16 |