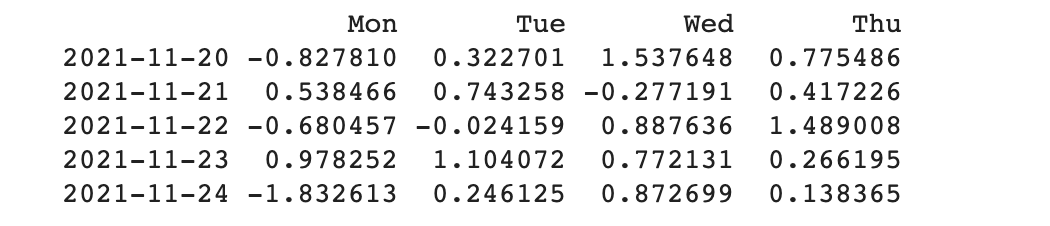
지난 포스팅에 이어 이번 포스팅은 Pandas 고급 사용법인 두 데이터를 병합하는 방법에 대하여 알아보겠습니다.
서로 다른 두 데이터 프레임을 병합해 보겠습니다.
병합을 통해 우리가 원하는 형태의 데이터 프레임을 만들 수 있습니다.
먼저 알아볼 병합 방식인 concat은 데이터를 기준 키(key) 없이 단순히 인덱스나 컬럼을 기준으로 병합을 진행해 줍니다.







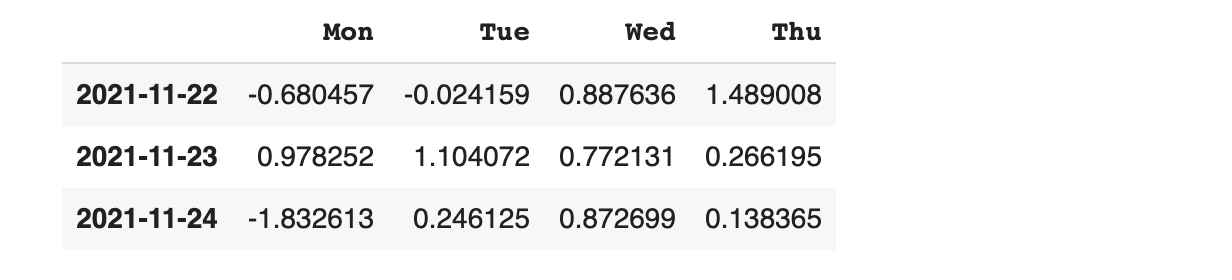
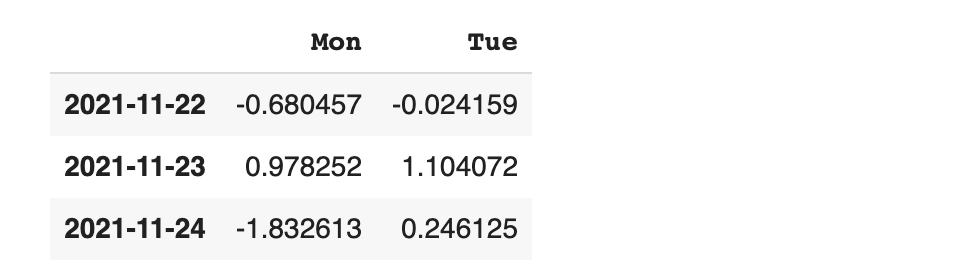
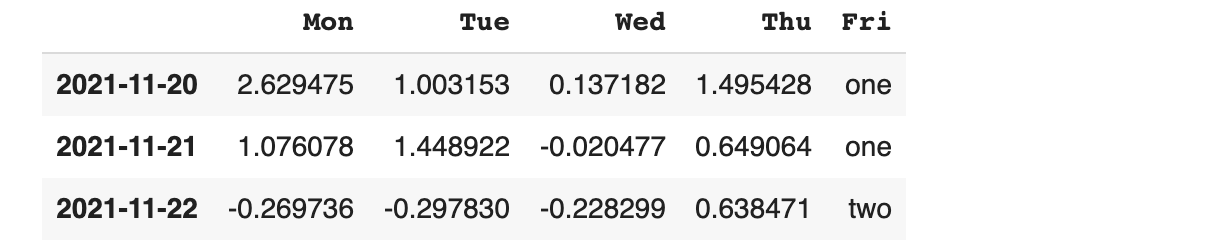
위의 데이터가 잘 확인 됐다면 단순히 열 방향(칼럼 기준)으로 합쳐 보겠습니다.
다른 옵션을 부여하지 않으면 자동으로 열 방향으로 병합됩니다.


특별히 keys 옵션을 활용하면 합쳐진 데이터 별 인덱스를 새로 부여할 수 있습니다.
인덱스가 왼쪽에 위치할수록 깊이가 얕습니다. 이 때 인덱스의 깊이를 level 이라고 합니다.

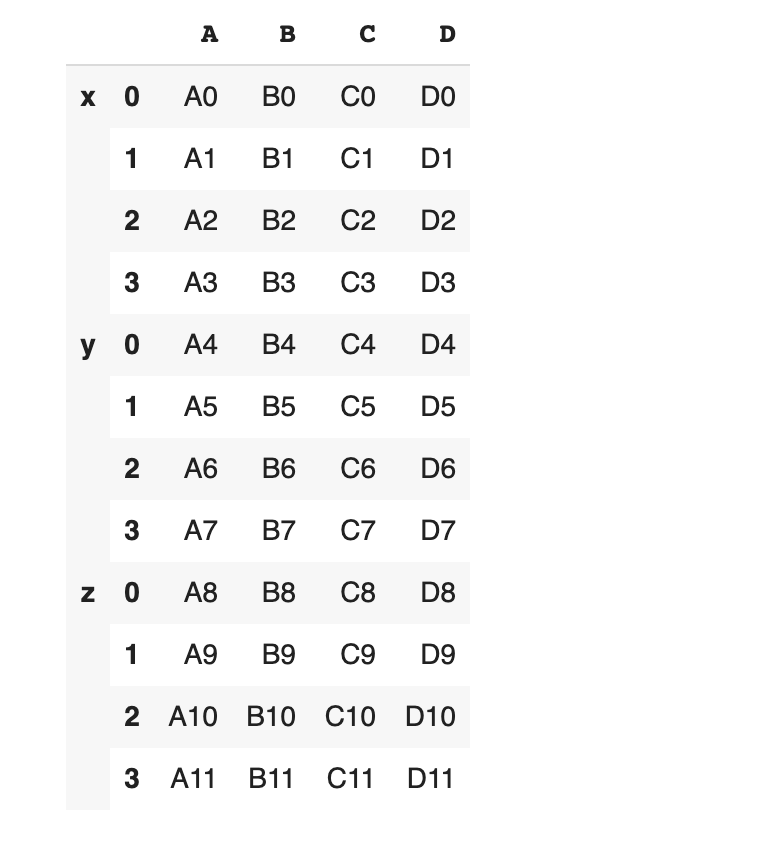
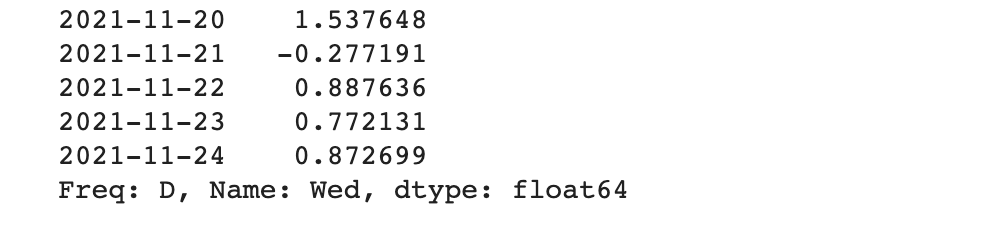
level을 확인해 보겠습니다.






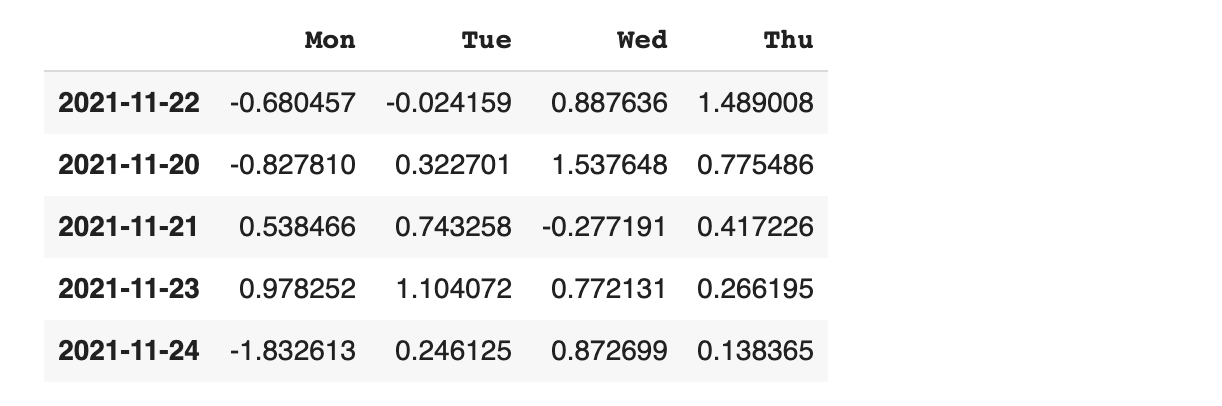
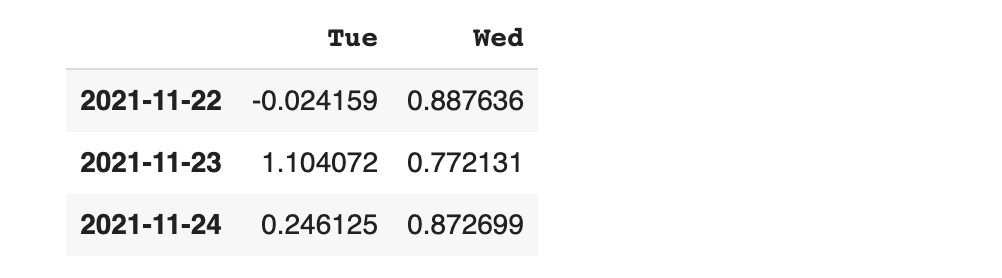
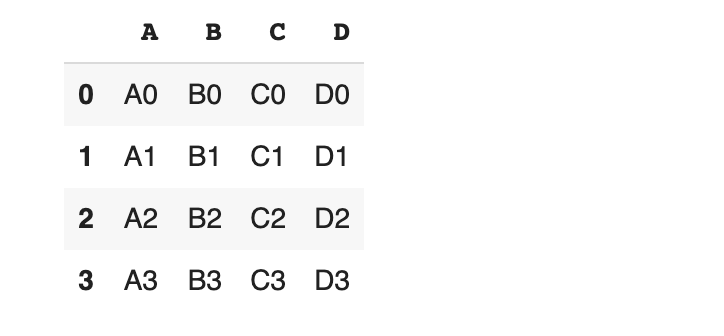
서로 다른 인덱스와 컬럼을 가진 데이터 프레임을 합쳐 보겠습니다.


df1도 확인 해 볼까요?

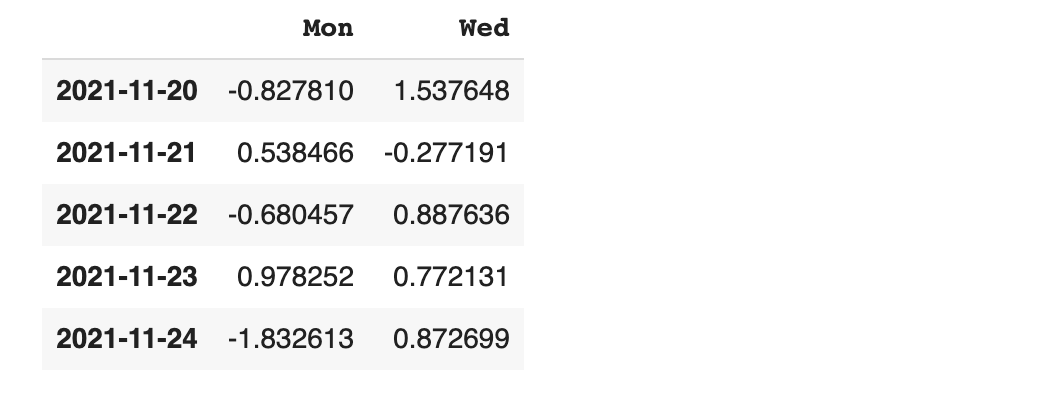
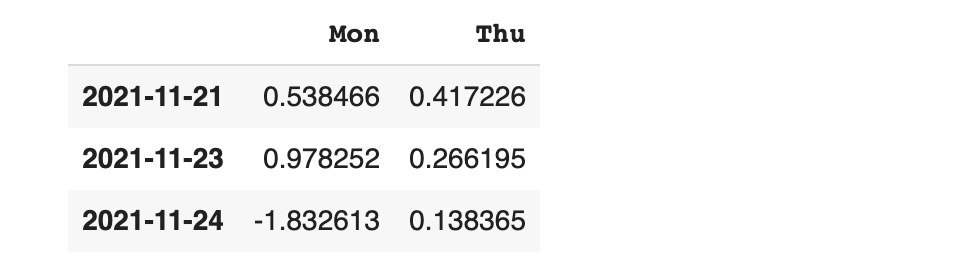
axis 옵션을 이용하면 행 (row - 가로방향) 기준 또는 열 (column - 세로 방향) 기준을 설정해 줄 수 있습니다.
- axis가 0이면 세로 병합 - 컬럼 기준
- axis가 1이면 가로 병합 - 인덱스 기준


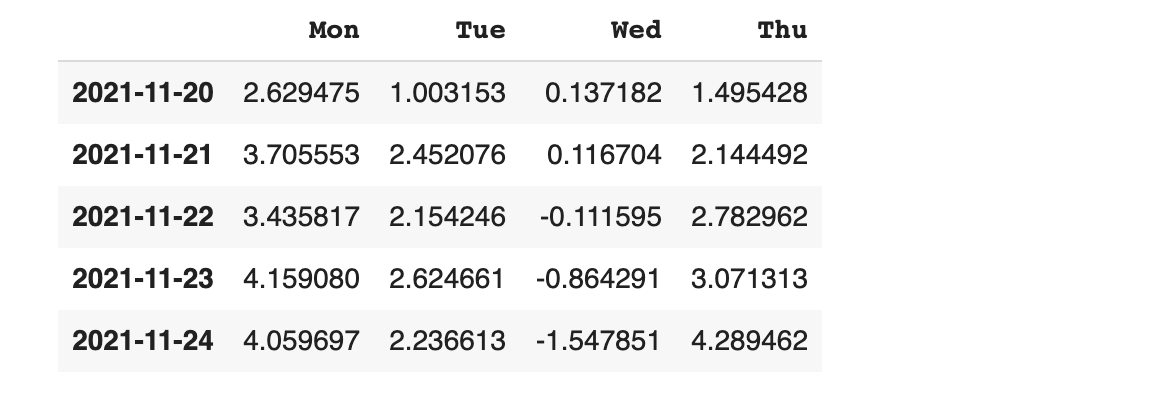
axis가 1이기 때문에 가로(row)로 병합이 되는 것이 확인이 됩니다.
문제는 NaN 데이터의 존재입니다.
각 데이터 프레림별 해당하는 인덱스에 알맞은 데이터가 존재하지 않기 때문에 표현할 수 없는 값은 NaN으로 표기됩니다.
예를 들어 df1은 원래 인덱스 6번이 없었는데 concat에 의해 병합되면서 인덱스가 부여가 되었습니다.
하지만, 6번 인덱스에 표현할 값이 없기 때문이고, 2번 인덱스에는 표현할 값이 있기 때문에 NaN 으로 처리되지 않습니다.
마찬가지로 df4는 인덱스 0번과 1번에 데이터가 없었기 때문에 데이터가 NaN으로 처리되고 있는 것입니다.
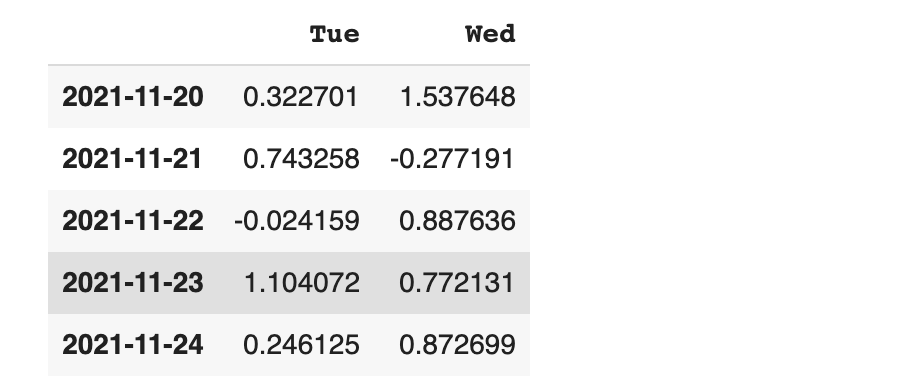
concat에 join='inner' 옵션을 부여하면 서로 공통적인 인덱스를 가진 행만 병합이 됩니다.
따라서 공통 인덱스가 아닌 행은 버리게 됩니다.


df1, df4의 공통 인덱스인 2번과 3번만 병합 되었습니다.
join_axes 옵션을 이용하면 기준 데이터 프레임의 인덱스를 지정해줄 수도 있습니다.
이는 합쳐지는 데이터 프레임에 기준 데이터 프레임과 동일한 인덱스가 없으면 해당 row는 버립니다.


기존 인덱스를 무시하고 합쳐지고 나서 새로운 인덱스를 부여하려면ignore_index=True 옵션을 사용하면 됩니다.
이번엔 세로 방향(row)으로 합쳐 보겠습니다.


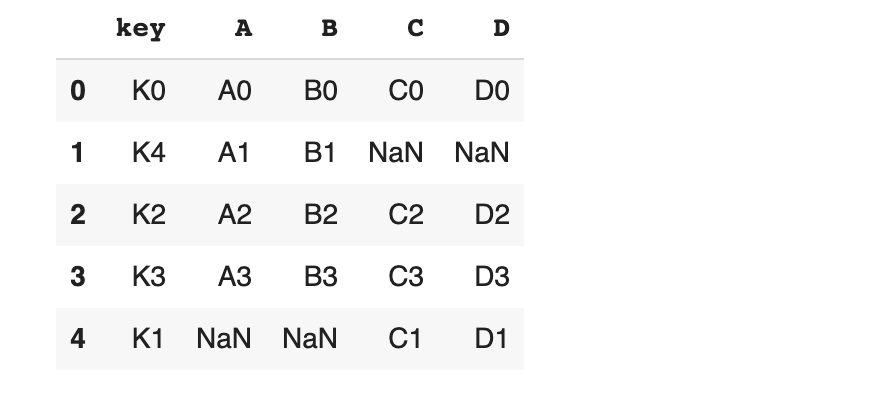
key가 되는 데이터를 기준으로 합쳐주는 merge
concat은 두 개의 데이터 프레임에 공통된 key가 되는 컬럼이 없을 때 사용할 수 있으나, merge는 두 개의 데이터 프레임에 공통으로 묶어 줄 수 있는 key값이 있을 때 사용 할 수 있습니다.





이제부터 공통으로 존재하는 칼럼인 key를 기준으로 merge 기준을 설정하는 on 옵션을 사용하여 공통된 key에 대해서만 합치게 만들어 보겠습니다.


how 옵션을 활용하여 기준이 되는 데이터 프레임을 지정할 수도 있습니다.




merge 했을 때 키값이 없더라도 일단 행을 채우고 싶다면(합집합처럼)how='outer'를 사용할 수 있습니다.
참고로, how='inner' 옵션은 첫 번째 merge처럼 공통된 키값에 대한 요소만을 갖습니다.



여기까지 Pandas의 고급 사용법 중 하나인 서로 다른 두 데이터 프레임을 병합해 보았습니다.
다음 포스팅부터는 이어서 CCTV 데이터와 인구현황 데이터를 합치고 분석해보도록 하겠습니다.
'Programming > Python' 카테고리의 다른 글
| [Python] Seaborn을 활용한 시각화 (+예제) (0) | 2021.04.05 |
|---|---|
| [Python] Matplotlib를 활용한 데이터 시각화 (0) | 2021.02.19 |
| [Python] Pandas DataFrame #pandas 기초 .01 (DataFrame 생성, 정제 및 준비, 삭제, Data 내보내기) (1) | 2021.02.04 |
| [Python]Data Visualisation # 시각화 기초 (Plot, Bar) (1) | 2021.02.03 |