이번 포스팅에서는 pandas의 기본 사용 방법에 대해서 이야기해보겠습니다.
파이썬 데이터 분석에는 pandas 사용 빈도가 매우 높습니다.
pandas는 기복적으로 python에서 데이터를 읽어와서 손쉽게 활용할 수 있게 해주는 모듈입니다.
이때 불러온 데이터를 데이터 프레임(Data Frame)이라고 합니다.

Series는 pandas의 가장 기본적인 자료형입니다.
list 형태로 데이터를 구성하여 data frame을 간단하게 만들 수 있습니다.


날짜 데이터 생성하기
data_range() 함수를 이용하여 날짜를 생성/수정할 수도 있습니다.
시작할 기본 날짜를 지정하고 periods옵션을 이용해 며칠간의 데이터를 발생시킬 것인지 지정해 줄 수 있습니다.


Data Frame 직접 생성하기
데이터 프레임을 직접 생성할 때 필요한 여러 가지 옵션들에 대해 간단히 정리하겠습니다.
첫 번째 인자에는 데이터 프레임을 채울 데이터가 입력됩니다.
iterable 자료구조로 만들어 낼 수 있습니다.(member를 하나씩 차례로 반환 가능한 object - list, str, tuple...)
index 옵션은 데이터 프레임의 인덱스로 지정할 값을 지정합니다.
columns 옵션은 데이터 프레임에서 사용할 컬럼들이 list 형태로 지정됩니다.
index 란 데이터 프레임의 행마다 순서대로 붙어있는 구분자를 의미합니다.

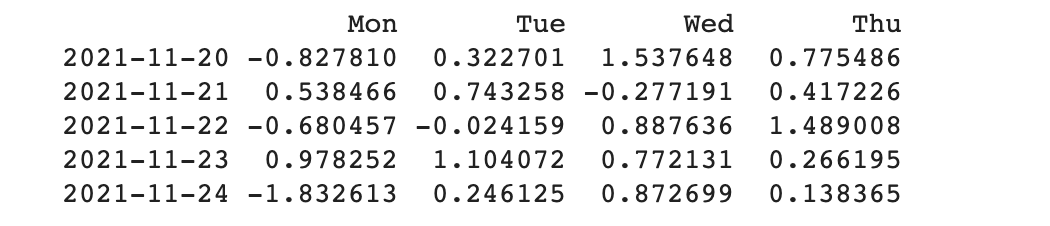
head() 함수를 사용하여 원하는 데이터만 확인할 수 있습니다.


데이터 프레임의 정보 확인하기
index : 데이터 프레임의 인덱스 확인


columns : 데이터 프레임의 컬럼 확인

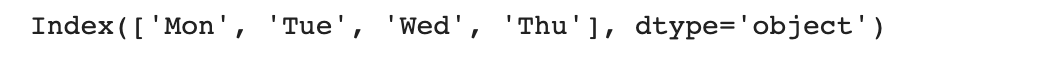
values : 데이터 프레임의 내부 값 확인하기


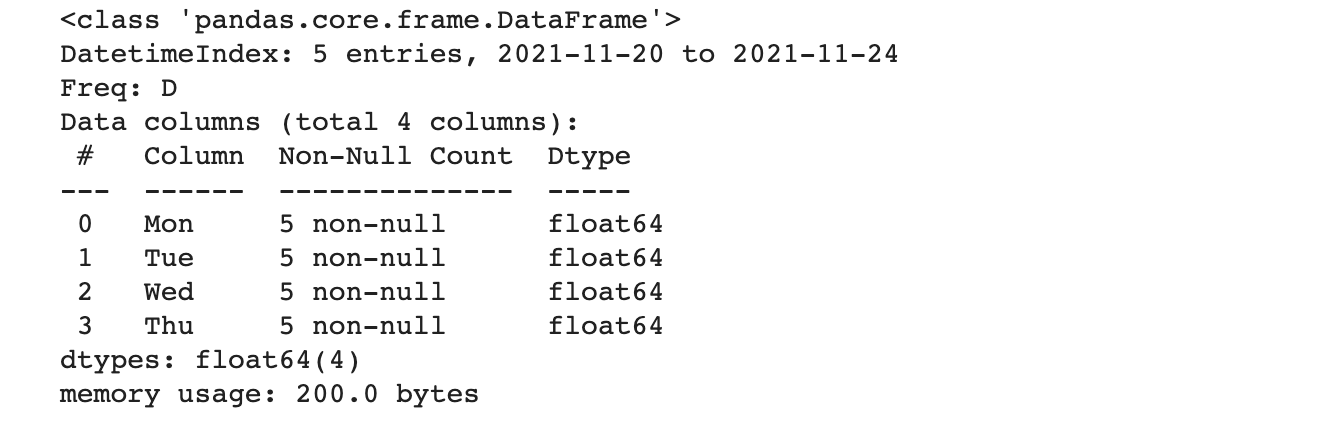
info() : 데이터 프레임의 간단한 개요 확인하기

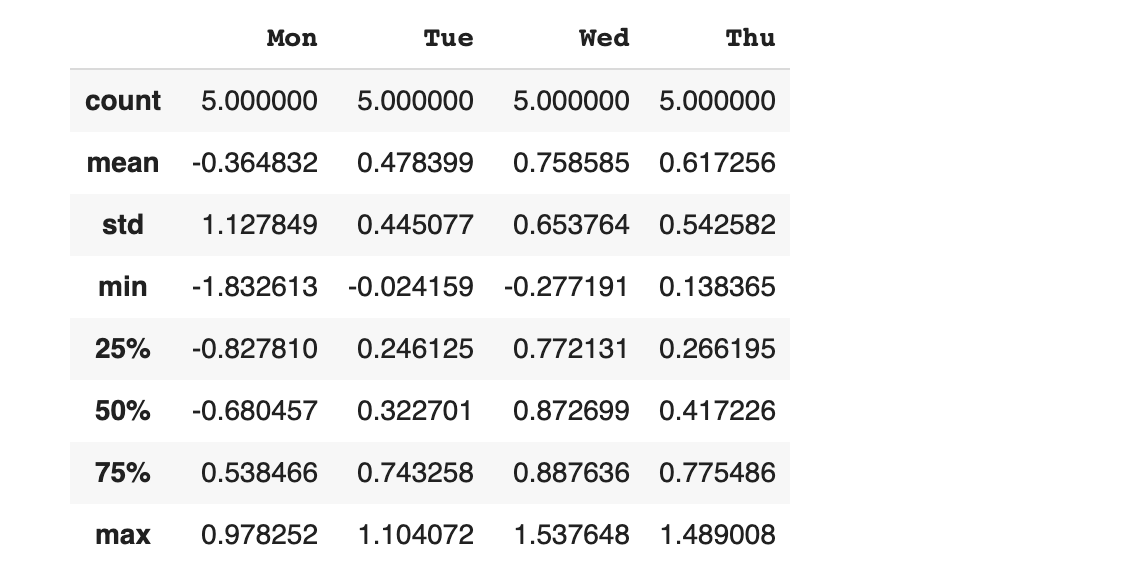
describe() : 통계적 개요 확인하기
데이터 개수 (count), 평균 (mean), 최솟값(min), 최댓값(max) 등

데이터 정렬(sort)
sort_values() 함수를 사용해 정렬을 할 수 있습니다.
이때 필요한 옵션은
by : 정렬 기준으로 삼을 컬럼을 지정
ascending : 내림차순(False), 오름차순(True) 지정

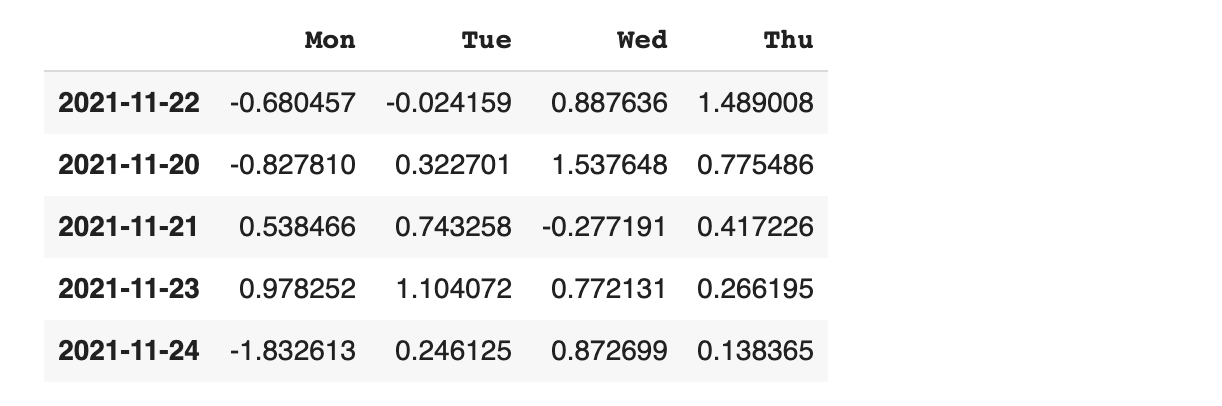
데이터 선택 확인
Data Frame에 원하는 컬럼 이름을 넣으면 Series 형태로 해당 컬럼의 데이터가 보입니다.

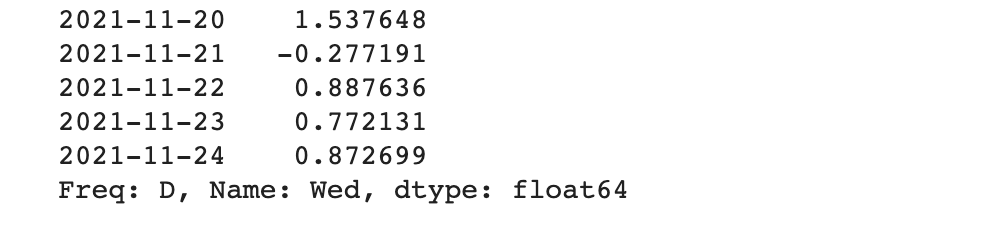
슬라이스 기법을 활용해서 출력 데이터 범위 지정하기
slice( [ start : end : step ] )을 데이터 프레임에 적용하면 원하는 범위의 데이터를 손쉽게 확인할 수 있습니다.


오프셋이 아닌 인덱스의 이름으로도 슬라이스가 가능합니다.

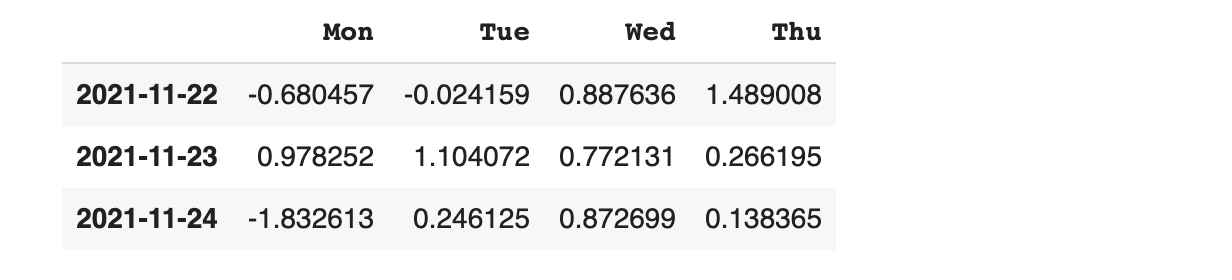
특정 위치의 데이터 확인하기 loc
특정 위치(location)의 데이터만 확인하고 싶을 때는 loc 함수를 사용할 수 있습니다.
loc 함수는 데이터 분석에서 정말 많이 이용되는 함수입니다.
첫 번째 인자는 행(row)을 뜻하고, 두 번째 인자는 열(column)을 뜻합니다.
dates 변수의 첫 번째 값을 활용해 해당하는 위치의 값 보기


직접 날짜를 지정해서 해당 날짜의 데이터를 확인하기


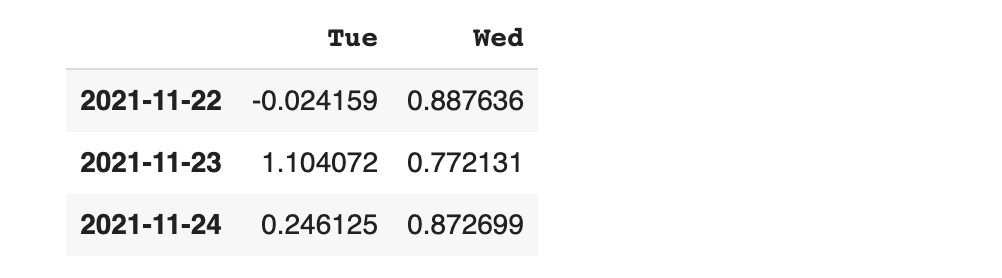
loc를 이용해 Mon, Wed 컬럼의 데이터들만 확인해 보겠습니다

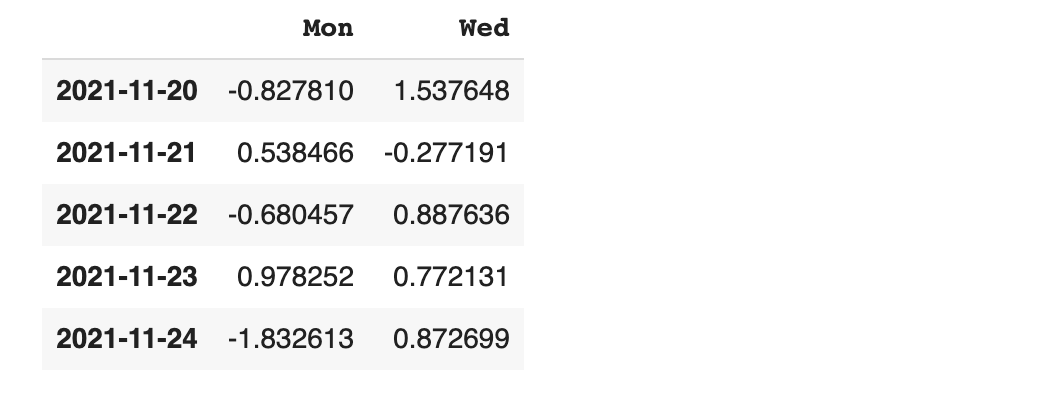
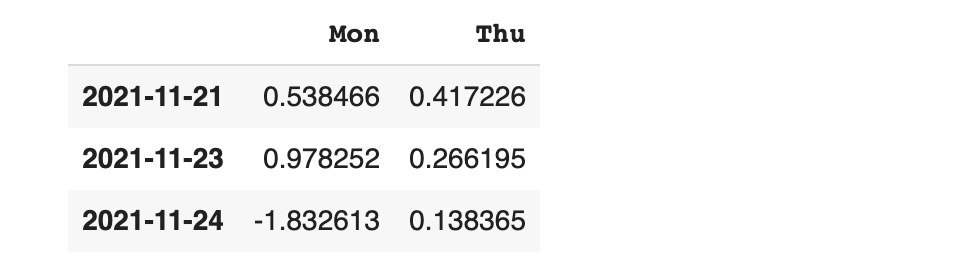
이번에는 행에다가도 범위를 지정해 보겠습니다

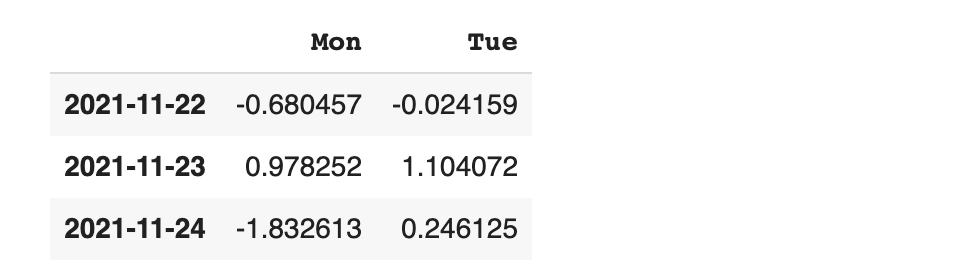
물론 날짜를 직접 지정해 볼 수도 있습니다


또는, 인덱스를 생성할 때 정의했던 변수를 사용해 볼 수도 있습니다


loc는 데이터의 값을 사용, iloc은 행과 열의 번호를 이용할 수 있습니다.
데이터 프레임이 가지고 있는 정확한 행, 열 이름을 정확히 모를 때는 번호(오프셋)를 사용해서 범위를 지정할 수 있습니다.







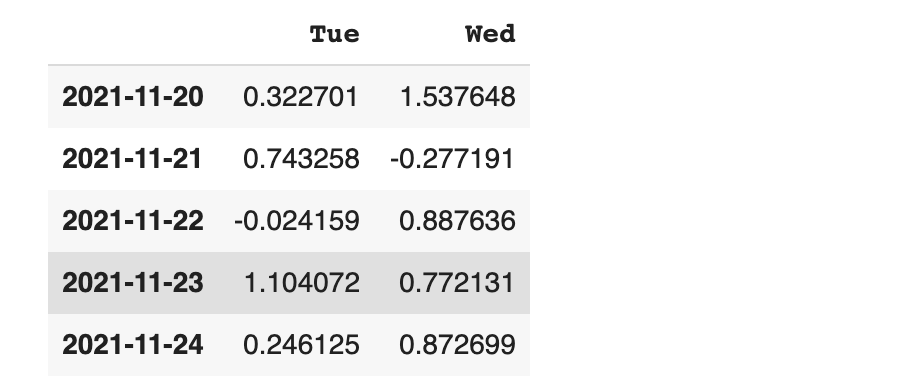
컬럼 선택을 다음과 같이도 할 수 있습니다.


데이터를 복사할 때는 copy() 함수를 사용
파이썬은 모두 객체죠?
할당과 복사를 다시 떠올려 보세요.
' = ' 만 사용하면 기존 객체가 변수에 할당됩니다.
따라서 copy() 메소드를 활용해 복사를 해야 합니다.


데이터 존재 유무 판단할 때는 isin 함수를 사용
현재 다루고 있는 데이터 프레임에 데이터가 존재하는지, 존재하지 않는지 True, False로 구분할 수 있습니다.
추후 데이터 분석 시에 조건으로써 활용될 수 있습니다.


isin을 조건으로써 활용하여 조건에 맞는 데이터만 가지고 와 보겠습니다

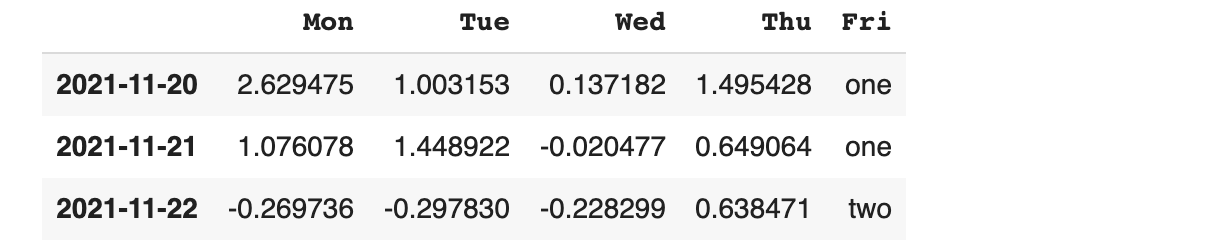
데이터 프레임에서 간단한 통계 형태로 데이터를 확인할 때는 apply() 함수를 활용
numpy 모듈과 같이 사용하면 간단하게 여러 통계적 데이터를 확인할 수 있습니다.

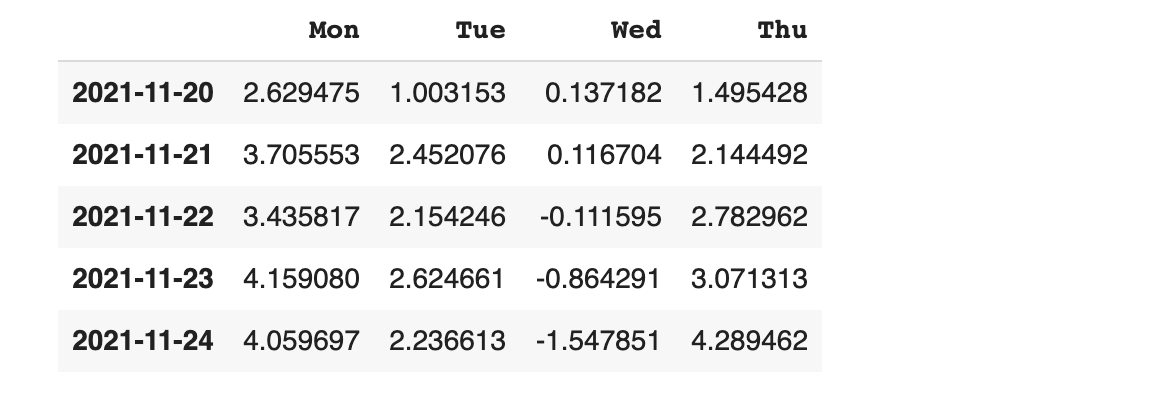
꼭 numpy 모듈이 아니더라도 우리가 직접 람다 함수를 만들어서 결과물을 확인 할 수도 있습니다.
최댓값 - 최솟값 ( 데이터들의 거리 ) 구하기

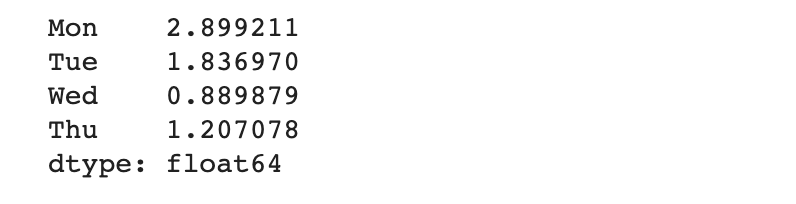
파이썬 데이터 분석을 위한 데이터 프레임을 pandas를 사용하여 간단하게 활용해보았습니다.
다음 포스팅에서 본격적으로 데이터 분석을 시작해 보겠습니다.
CCTV와 서울시 인구현황 예제로 시작하겠습니다
'Programming > 통계 데이터 분석' 카테고리의 다른 글
| [Python] pivot_table을 활용해 원하는 기준 만들기 (0) | 2021.04.02 |
|---|---|
| [Python] CCTV 현황 그래프로 분석하기 (0) | 2021.04.01 |
| [Python]CCTV 데이터와 인구 현황 데이터를 합치고 분석하기 (0) | 2021.02.18 |
| [Python] 서울시 CCTV data와 인구현황 data 파악하기 (0) | 2021.02.15 |
| [Python] Pandas를 활용한 파이썬에서 csv, excel 파일 읽어오기 (0) | 2021.02.05 |