이번 포스팅에서는 의사결정 트리(Decision Tree)에 대하여 알아보도록 하겠습니다!
결정 트리(Decision Tree)
분류와 회귀 문제에 널리 사용하는 모델입니다. 기본적으로 결정 트리는 스무고개 놀이와 비슷합니다. 던지는 질문에 Yes / No를 결정해 문제를 해결합니다.
#필요 라이브러리 임포트
from IPython.display import display
import numpy as np
import matplotlib.pyplot as plt
import pandas as pd
import mglearn
from sklearn.model_selection import train_test_split
import platform
import graphviz
plt.rcParams['axes.unicode_minus'] = False
%matplotlib inline
path = 'c:/Windows/Fonts/malgun.ttf'
from matplotlib import font_manager, rc
if platform.system() == 'Darwin':
rc('font', family='AppleGothic')
elif platform.system() == 'Windows':
font_name = font_manager.FontProperties(fname=path).get_name()
rc('font', family=font_name)
else:
print('Unknown system... sorry!')mglearn.plots.plot_animal_tree()
4가지 동물( 매, 펭귄, 돌고래, 곰 )을 구분하는 모습을 보여주고 있습니다. 이 그림에서 트리의 노드는 질문이나 정답을 담은 네모 상자입니다.
마지막 정답이 들어있는 노드는 리프라고도 이야기합니다.
머신러닝 식으로 이야기하자면 "날개가 있나요"?, "날 수 있나요?", "지느러미가 있나요?"를 이용해 네 개의 클래스를 구분하는 모델을 만든 것입니다. 이런 모델을 직접 만드는 것이 아닌 지도 학습 방식으로 데이터로부터 학습할 수 있습니다.
결정 트리 만들기
2차원 데이터셋을 분류하는 결정트리를 만들어 봅시다. 이 데이터셋은 각 클래스에 데이터 포인트가 75개씩 존재합니다. 그리고 반달 두 개가 포개진듯한 모양을 하고 있습니다.
이 데이터셋을 two_moons라고 합니다.
결정 트리를 학습한다는 것은 정답에 가장 빨리 도달하는 예 / 아니오 질문 목록을 학습한다는 뜻입니다. 머신러닝에서는 이런 질문들을 테스트 라고합니다. ( 테스트 세트라고 생각하면 절대 안도미!)
위의 동물 예제처럼 예 / 아니오 형태의 특성으로 구성되지 않고, 2차원 데이터셋과 같이 연속된 특성으로 구성됩니다. 즉 "특성 𝑖는 값 𝑎 보다 큰가?"와 같은 형태입니다.
mglearn.plots.plot_tree_progressive()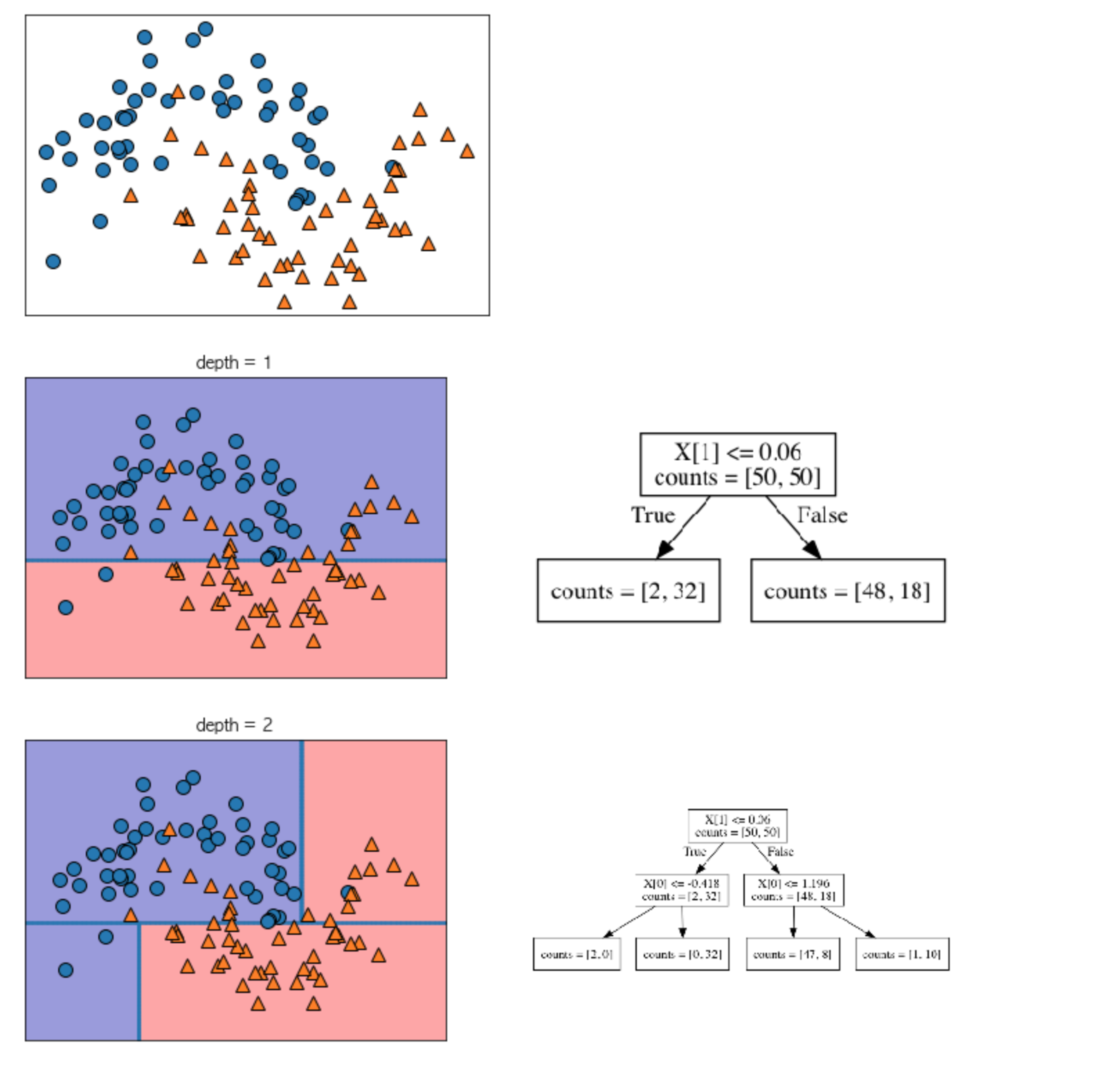

알고리즘 고르기
트리를 만들 때 알고리즘은 가능한 모든 테스트에서 타깃값에 대해 가장 많은 정보를 가진 것을 고릅니다.
depth 1
트리의 깊이가 1인 상태에서의 테스트를 사려 보겠습니다. 데이터셋을 X [1] = 0.06에서 수평으로 나누는 것이 가장 많은 정보를 포함시키고 있습니다.
즉 이 직선이 0에 속한 포인트와 클래스 1에 속한 포인트를 가장 잘 나누고 있습니다. 파란 점은 클래스 0을 의미하며, 세모는 클래스 1을 의미합니다.
루트 노드라고도 이야기하는 맨 위 노드는 클래스 0에 속한 포인트 75개와 클래스 1에 속한 포인트 75개를 모두 포함한 전체 데이터셋을 의미합니다.
X [1] <= 0.6 테스트에 의해 true가 된 것들은 왼쪽 노드에 할당되고, 그렇지 않은 것들은 오른쪽에 할당됩니다.
왼쪽 노드에는 클래스 0에 속한 포인트는 2개, 클래스 1에 속한 포인트는 32개입니다. 오른쪽 노드에는 클래스 0에 속한 포인트는 48개, 클래스 1에 속한 포인트는 18개 있는 것으로 확인되네요
이 두 노드는 첫 번째 그림의 윗부분과 아랫부분으로 각각 분류됩니다.
대부분 잘 분류하기는 했지만 아직 완벽하게 분류하진 못한 것 같습니다.
depth 2
트리의 깊이가 2인 상태에서는 깊이가 1인 상태에서 보다 조금 더 각 클래스 별 정보를 영역에 담을 수 있도록 X [0] 값을 기준으로 왼쪽과 오른쪽 영역으로 나누고 있습니다.
이렇게 계속되는 테스트 ( 반복되는 프로세스 )는 각 노드가 테스트 하나씩을 가진 이진 결정 트리를 만들어 냅니다. 다르게 말하며 각 테스트는 하나의 축을 따라 데이터를 둘로 나누는 것이라고 생각해 볼 수도 있습니다. 이는 계층적으로 영역을 분할해 가는 알고리즘이라고 할 수 있습니다.
데이터를 분할하는 것은 각 분할된 영역이 ( 결정 트리의 리프 ) 한 개의 타깃값 ( 하나의 클래스나 하나의 회귀 분석 결과)을 가질 때까지 반복됩니다.
각 테스트는 하나의 특성에 대해서만 이루어지기 때문에 나누어진 영역은 항상 평행합니다. 이때 타깃 하나로만 이뤄진 리프 노드를 순수 노드(pure node)라고 합니다.
depth 9
순수 노드가 존재하는 최종 분할 트리라고 할 수 있는 깊이가 9인 상태를 보면 잘 보이지는 않지만 더 이상 분할 하지 않고 값을 결정 지어버리는 노드도 있습니다. 이 노드들이 위에서 이야기했던 순수 노드입니다.
결론
새로운 데이터 포인트에 대한 예측은 주어진 데이터 포인트가 특성을 분할한 영역들 중 어디에 놓이는지를 확인해 보면 됩니다.
- 타깃 값중 다수를 차지하는 노드
- 순수 노드로 결정 지어지는 경우
위의 두 가지로 예측결과를 지정합니다.
루트 노드에서 시작해 테스트의 결과에 따라 왼쪽 또는 오른쪽으로 트리를 탐색해 나가는 식으로 영역을 찾아낼 수 있습니다.
같은 방법으로 회귀 문제에도 트리를 사용할 수 있습니다. 예측을 하러면 각 노드의 테스트 결과에 따라 트리를 탐색해 나가고 새로운 데이터 포인트에 해당되는 리프 노드를 찾습니다. 찾은 리프 노드의 훈련 데이터 평균값이 이 데이터 포인트의 출력이 됩니다.
결정 트리 복잡도 제어
트리를 만들어 낼 때 모든 리프가 순수 노드가 될 때까지 진행한다면 모델이 매우 복잡해지고 훈련 데이터에 과대 적합합니다. 득 훈련 세트에 100% 정확하게 맞는다는 의미가 됩니다.
즉 순수 노드는 정확학 클래스의 리프노드라고 볼 수 있습니다. depth 9 일 때의 그림을 보시면 왼쪽 그래프가 굉장히 과대적합 되었다고 볼 수 있습니다.
클래서 1로 결정된 영역이 클래스 0에 속한 포인트들로 둘러싸인 것을 볼 수 있는데, 그 반대의 모습도 찾아볼 수 있습니다.
결정 경계가 클래스의 포인트들에서 멀리 떨어진 이상치(outlier)에 너무 민감해지기 때문이죠
과대적합 막기
과대적합을 막으려면 크게 두 가지로 전략을 세워야 합니다.
- 트리 생성을 일찍 중단( 사전 가지치기 ( Pre pruning ) )
- 트리를 다 만들고 데이터 포인트가 적은 노드를 삭제하거나 병합 ( 사후 가지치기( Post pruning ) )
먼저 사전 가지치기 방법은 트리의 최대 깊이나 리프의 최대 개수를 제한하거나 노드가 분할하기 위한 포인트의 최소 개수를 지정하는 것입니다.
scikit-learn에서 결정트리는 DecisionTreeRegressor와 DecisionTreeClassifier에 구현되어 있습니다. 사전 가지치기 만을 지원합니다.
유방암 데이터 셋을 이용해 사전 가지치기의 효과에 대해서 알아보겠습니다. 기본값 설정으로 완벽한 트리 ( 모든 리프 노드가 순수 노드가 될 때까지 생성한 트리 ) 모델을 만들어 봅니다.
from sklearn.datasets import load_breast_cancer
from sklearn.tree import DecisionTreeClassifier
cancer = load_breast_cancer()
X_train, X_test, y_train, y_test = train_test_split(cancer.data, cancer.target, stratify=cancer.target, random_state=42)
tree = DecisionTreeClassifier(random_state = 0)
tree.fit(X_train, y_train)
print("훈련 세트 정확도 : {:.3f}".format(tree.score(X_train, y_train)))
print("테스트 세트 정확도 : {:.3f}".format(tree.score(X_test, y_test)))
생각 한대로 모든 리프가 순수 노드이기 때문에 훈련 세트의 정확도는 100%입니다. 즉 트리는 훈련 데이터의 훈련 데이터의 모든 레이블을 완벽하게 기억하고 있을 만큼 충분히 깊습니다.
테스트 세트의 정확도는 이전에 본 선형 모델에서의 정확도인 95% 보다 약간 낮습니다.
결정 트리의 깊이를 제한하지 않으면 트리는 무한정 깊어지고 복잡해질 수 있습니다. 따라서 가지치기를 하지 않은 트리는 과대적합 되기 쉽고 새로운 데이터에 잘 일반화되지 않습니다.
사전 가지치기 적용
이제 유방암 데이터셋을 위한 결정 트리에 사전 가지치기를 통해 트리가 깊어지는 것을 막아 보겠습니다. 방법은 트리가 훈련 데이터에 완전히 학습되기 전에 트리의 성장을 막아보는 것입니다. max_depth 매개변수를 이용하며, 유방암 데이터셋에서는 4 옵션을 줘서 막을 수 있습니다. 즉 연속된 질문을 4개로 제한하게 됩니다.
트리의 깊이를 제한하면 과대적합이 줄어듭니다. 이는 훈련 세트의 정확도를 떨어뜨리지만 테스트 세트의 성능을 개선시킵니다.
tree = DecisionTreeClassifier(max_depth=4, random_state=0)
tree.fit(X_train, y_train)
print("훈련 세트 정확도 : {:.3f}".format(tree.score(X_train, y_train)))
print("테스트 세트 정확도 : {:.3f}".format(tree.score(X_test, y_test)))
다음 블로그에서는 앞서 다룬 Tree의 시각화 및 특성 중요도에 대하여 알아보고 결정 트리의 장단점에 대하여 알아보도록 하겠습니다.
'Programming > 특성 공학' 카테고리의 다른 글
| [Machine Learning] 앙상블 모델(Random Forest & Gradient Boosting) (0) | 2023.06.06 |
|---|---|
| [Machine Learning] 의사결정 트리(Decision Tree) 시각화 (0) | 2023.05.30 |
| [Machine Learning] 다중 선형 분류 (0) | 2023.05.16 |
| [Machine Learning] 선형 이진 분류 (0) | 2023.05.09 |
| [Machine Learning] 선형 회귀 (0) | 2023.05.02 |