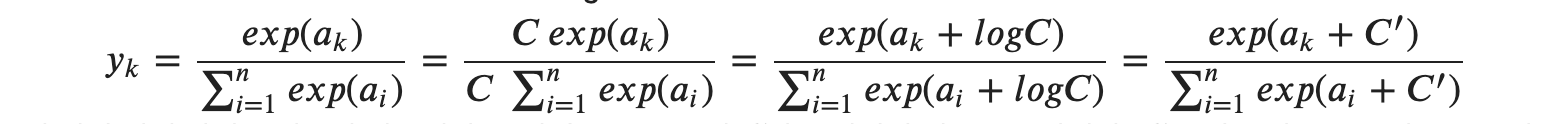지난 시간 역전파의 덧셈과 곱셈 노드에 대하여 알아보는 시간을 가졌습니다.
2024.02.22 - [Programming/Deep Learning] - [Python/DeepLearning] #10.4. 역전파) 덧셈 노드와 곱셈 노드
[Python/DeepLearning] #10.4. 역전파) 덧셈 노드와 곱셈 노드
지난 글을 통해 계산 그래프의 역전파가 연쇄 법칙에 따라서 진행되는 모습을 이야기해 보았습니다. 2024.02.15 - [Programming/Deep Learning] - [Python/DeepLearning] #10.3. 역전파) 계산 그래프ᄅ
yuja-k.tistory.com
이번 시간에는 역전파의 완전 마지막! 활성화 함수 계층을 구현해 보도록 하겠습니다! 이 이상의 #10을 쪼개진 않겠습니다...

활성화 함수 계층 구현
드디어 지금 만든 계산 그래프를 신경망에 적용시켜 볼 수 있습니다!
여기에서는 신경망을 구성하는 층(계층) 각각을 클래스 하나씩으로 구현했는데요. 우선은 활성화 함수인 ReLU와 Sigmoid 계층을 구현해 보겠습니다!
ReLU 계층 만들기
먼저. 활성화 함수로 사용되는 ReLU의 수식은 다음과 같습니다.

위의 식을 미분하면 다음처럼 구할 수 있습니다.

순전파 때의 입력인 x가 0보다 크면 역전파는 상류의 값을 그래도 하류로 흘립니다.
반면에 순전파 때 x가 0 이하면 역전파 때는 하류로 신호를 보내지 않습니다.( 0을 보내기 때문입니다).
계산 그래프로는 다음 처럼 그릴 수 있겠네요!

그럼 본격적으로 ReLU 계층을 구현해 보도록 하겠습니다!
신경망 계층의 forward()와 backward() 함수는 넘파이 배열을 인수로 받는다고 가정합니다.
신경망 레이어 만들기
- ReLU
- Sigmoid
- Affine layer( 기하학 레이어 - Fully Connected, Dense )
- SoftMax + Loss layer
ReLU 구현
class ReLU:
# mask : 순전파 시에 0이나 음수였던 인덱스를 저장하기 위함이다.
# mask가 있어야 순전파 때 0이었던 부분을 역전파 때 0으로 만들어 줄 수 있다.
def __init__(self):
self.mask = None
def forward(self, x):
self.mask = (x <= 0)# 매개변수로 들어온 넘파이배열 x의 원소가 0이하인지 판단하기
out = x.copy() # 원본 배열 복사
out[self.mask] = 0 # 0보다 작은 원소들을 0으로 만들기
return out
# 순전파 때 음수였던 부분을 0으로 만든다.
# 음수였었던 인덱스를 기억하고 있다가 (self.mask) 미분값 전달시에 해당 인덱스를 0으로 만든다.
def backward(self, dout):
dout[self.mask] = 0 # 상류에서 들어온 값에서 0보다 작은 값들에 대해 0으로 치환
dx = dout # 완성된 ReLU 배열 리턴
return dx완성된 ReLU 계층을 np.array 배열을 넣어서 테스트해보겠습니다.
x = np.array([ [1.0, -0.5],
[-2.0, 3.0] ])
print(x)
relu = ReLU()
relu.forward(x)
relu.mask
dx = np.array([ [-0.1, 4.0],
[1.3, -1.1] ])
relu.backward(dx)
Sigmoid 계층 만들기
다시 한번 시그모이드 함수를 살펴보도록 하죠!
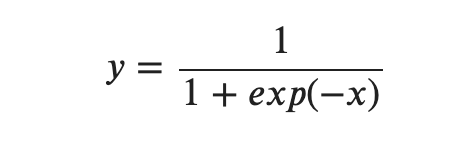
위 식을 계산 그래프로 그리면 다음과 같습니다.
X와 + 노드 말고 exp와 '/' 노드가 새롭게 등장했는데요, exp 노드는 𝑦=𝑒𝑥𝑝(𝑥) 계산을 수행하고, '/' 노드는 𝑦=1𝑥를 수행합니다. 그림과 같이 시그모이드의 계산은 국소적 계산의 순전파로 이루어집니다. 이제 역전파를 알아볼 텐데요, 각 노드에 대한 역전파를 단계별로 알아보도록 하겠습니다.
1단계
'/' 노드를 미분하면 다음과 같습니다.
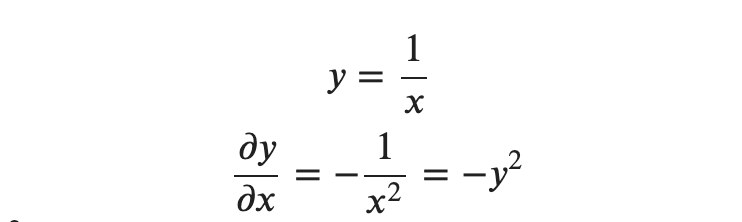
위처럼 상류에서 흘러 들어온 값에 −𝑦2(순전파의 출력을 제곱한 후 음수를 붙인 값)을 곱해서 하류로 전달시키게 됩니다. 계산 그래프에서는 다음과 같습니다.
2단계
'+' 노드는 상류의 값을 여과 없이 하류로 보냅니다. 계산 그래프의 결과는 다음과 같아집니다.
3단계
'exp'노드는 𝑦=𝑒𝑥𝑝(𝑥) 연산을 수행하며, 그 미분은 다음과 같습니다.
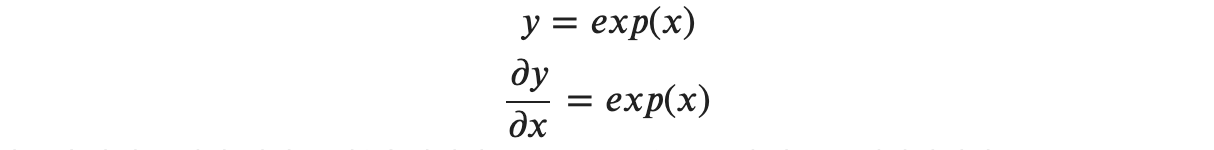
계산 그래프에서는 상류의 값에 순전파 때의 출력(이 예에서는 𝑒𝑥𝑝(−𝑥))을 곱해 하류로 전파합니다.
4단계
제일 마지막 X 노드는 순전파 때의 값을 서로 바꿔 곱합니다. 이 예에서는 -1을 곱하면 될 것 같습니다.
총 4 단계를 거쳐 Sigmoid 계층의 역전파를 계산 그래프로 완성해 보았습니다. 역전파의 최종출력인 ∂𝐿/∂𝑦*𝑦2*𝑒𝑥𝑝(−𝑥)) 값이 하류 노드로 전파됩니다. 그런데 ∂𝐿/∂𝑦*𝑦2*𝑒𝑥𝑝(−𝑥)를 순전파의 입력 𝑥와 출력 𝑦만으로 계산할 수 있다는 것을 알 수 있는데요, 따라서 계산 중간 과정을 모두 묶어서 다음처럼 단순한 그림으로 표현이 가능합니다.
또한 ∂𝐿/∂𝑦*𝑦2*𝑒𝑥𝑝(−𝑥)는 다음 처럼 정리할 수 있습니다.
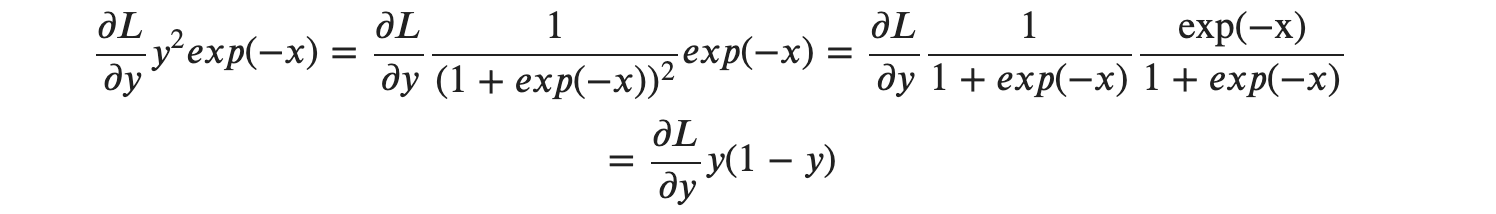
이처럼 Sigmoid 계층의 역전파는 순전파의 출력 y 만으로도 계산할 수 있습니다.
그렇다면, Sigmoid 계층을 파이썬으로 직접 만들어 보겠습니다.
Sigmoid 구현하기
class Sigmoid:
def __init__(self):
self.out = None
# 순전파
def forward(self, x):
out = 1 / ( 1 + np.exp(-x) )
self.out = out
return out
# 역전파
def backward(self, dout):
dx = dout * self.out * (1.0 - self.out)
return dx
이 구현은 단순히 순전파의 출력을 인스턴스 변수 out에 보관했다가, 역전파 계산 때 그 값을 사용합니다.
지금까지 역전파의 단계별 구현을 해보았습니다.
다음 시간에는 오차역전파의 Affine/Softmax 계층 신경망의 순전파에 대하여 구현해 보도록 하겠습니다.
'Programming > Deep Learning' 카테고리의 다른 글
| [Python/DeepLearning] #10.4. 역전파) 덧셈 노드와 곱셈 노드 (0) | 2024.02.22 |
|---|---|
| [Python/DeepLearning] #10.3. 역전파) 계산 그래프를 통한 역전파 이해 (1) | 2024.02.15 |
| [Python/DeepLearning] #10.2. 역전파) 수식을 통한 오차역전파법 이해 (0) | 2024.02.08 |
| [Python/DeepLearning] #10.1. 역전파) 합성함수의 미분과 연쇄법칙 (1) | 2024.02.06 |
| [Python/DeepLearning] #9.3. MNIST 신경망 구현하기 (2) | 2024.02.02 |