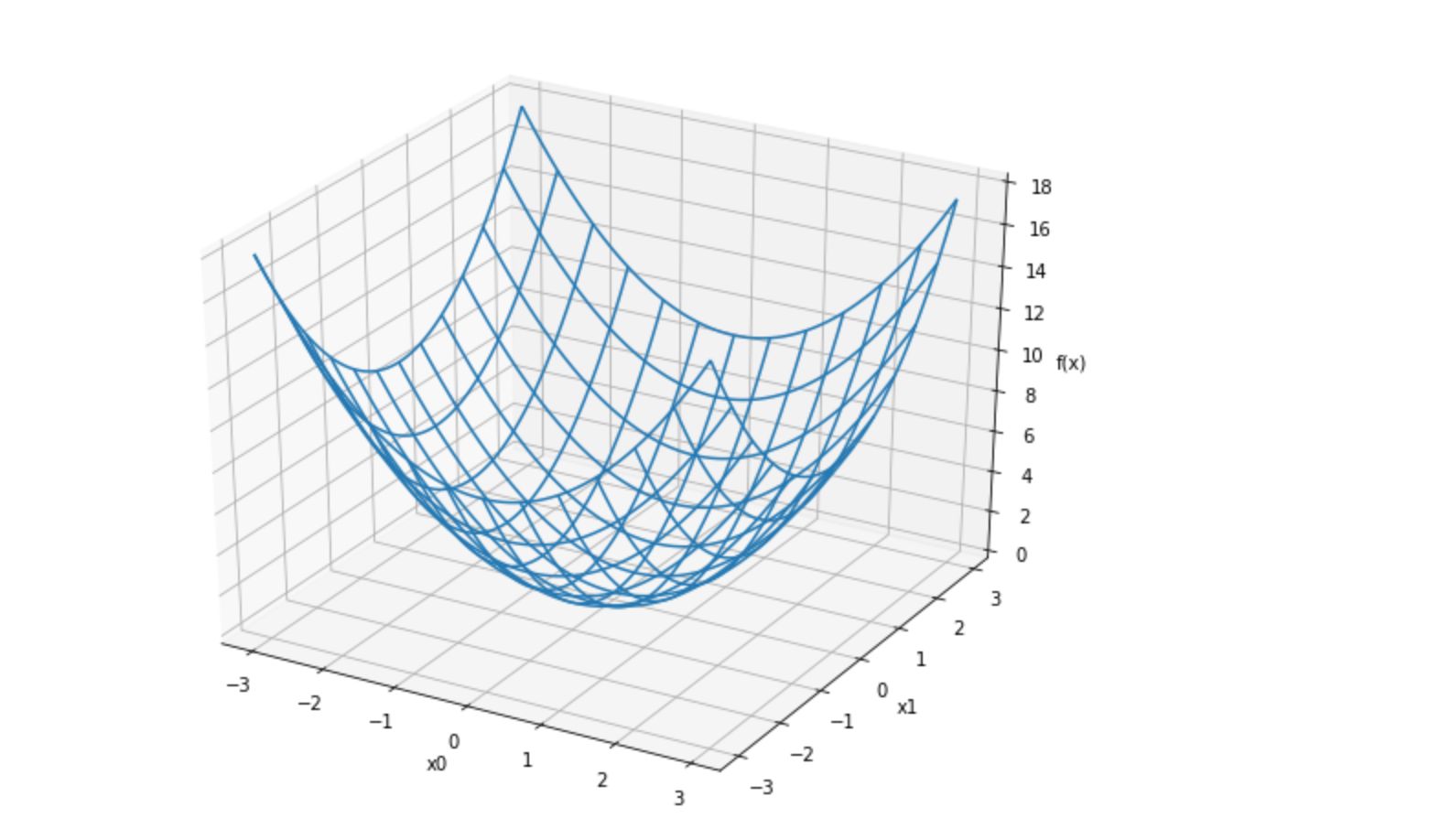
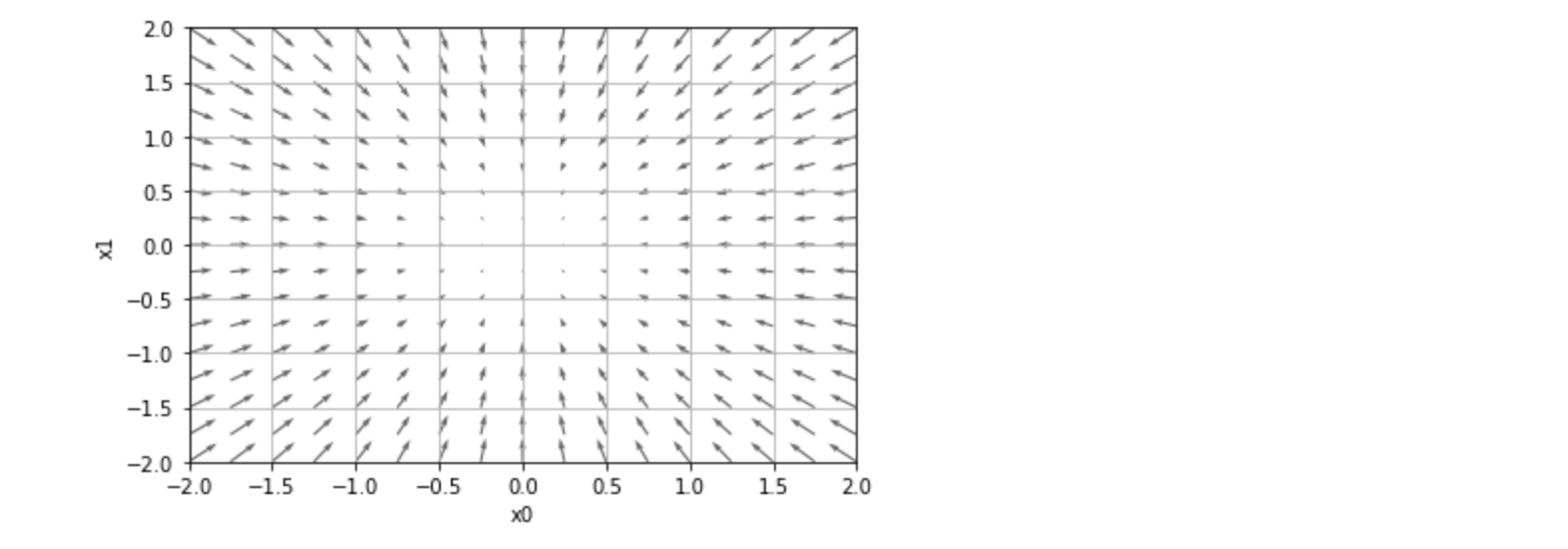
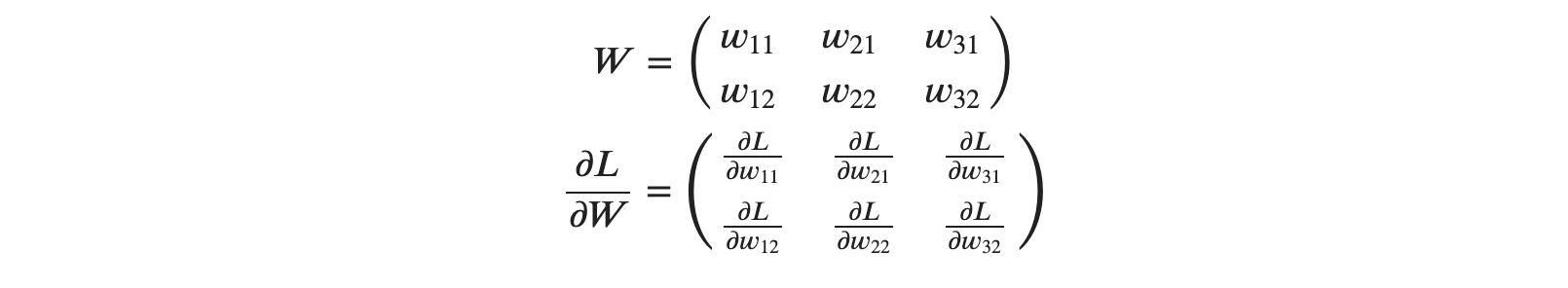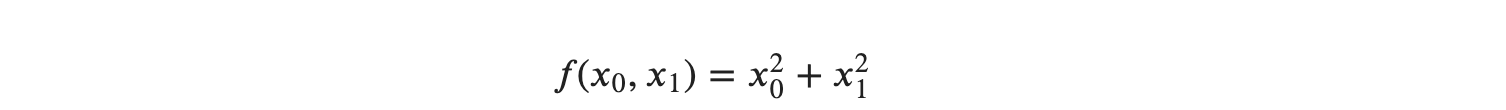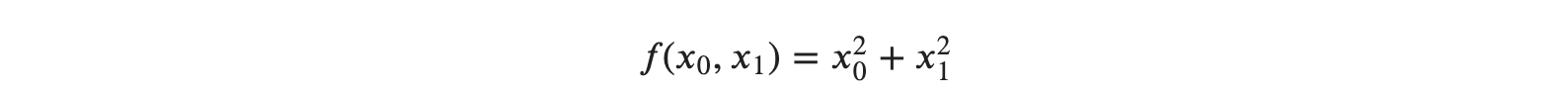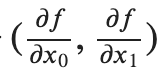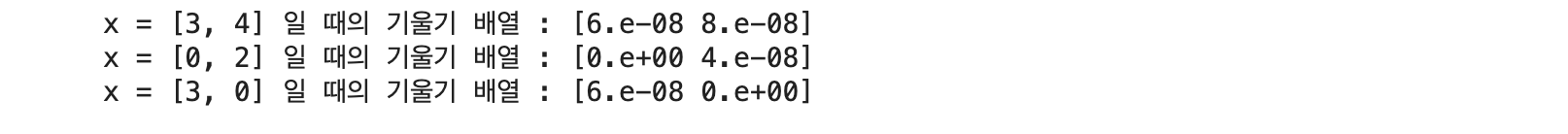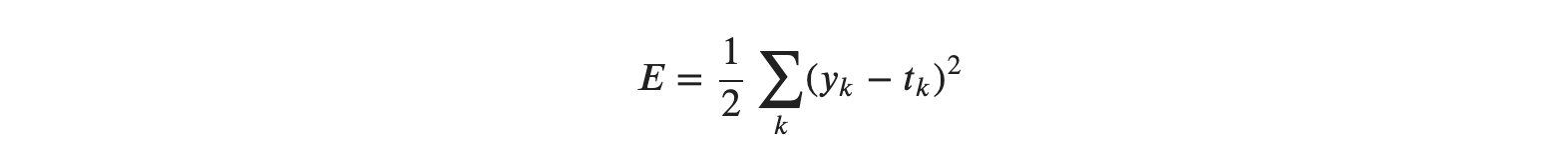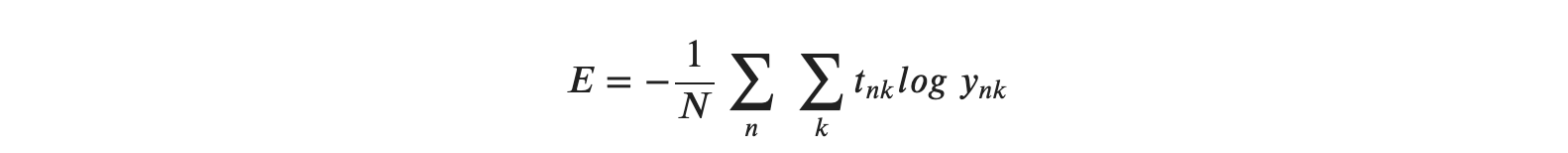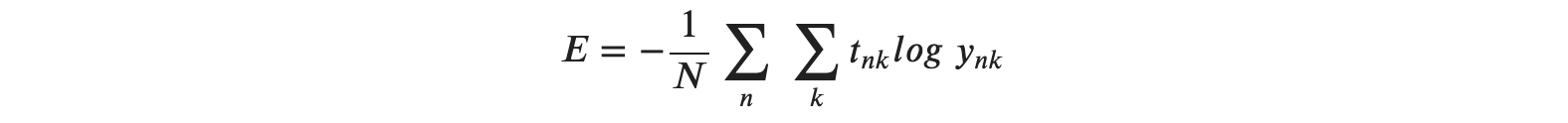지난 글로, 경사법(경사하강법)의 원리와 신경망에서의 기울기에 대한 신경망 학습을 알아보았습니다.
2024.01.31 - [Programming/Deep Learning] - [Python/DeepLearning] #9.2. 수치 미분과 경사하강법(하)
최종_최종_최종. 신경망 구현으로 오늘은 MNIST 데이터셋을 이용한 2층 신경망(은닉층이 1개인 네트워크)을 구현해 보겠습니다!
MNIST 신경망 구현하기
- 2층 신경망
- 1층 은닉층의 뉴런 개수는 100개
- 활성화 함수로 시그모이드 사용
- 2층 출력층의 뉴런 개수는 10개
- softmax를 사용함
- loss는 cross entropy error 사용할 것
- predict에서 softmax 적용할 것
- 내부에 기울기 배열을 구하는 numerical_gradient 구현
- 경사하강법을 여기서 구현하는 것은 아닙니다!
from common.functions import *
from common.gradient import numerical_gradient
class TwoLayerNet:
# input_size : 입력 데이터 shape( 이미지 크기 ( 28 * 28 ))
# hidden_size : 은닉층의 뉴런 개수
# output_size : 출력층의 뉴런 개수
# weight_init_std : 정규분포 랜덤값에 표준편차를 적용하기 위함
def __init__(self, input_size, hidden_size, output_size, weight_init_std=0.01):
# 나중에 매개변수(W, B)들은 경사하강법으로 모두 한꺼번에 업데이트가 되어야 해요
self.params = {}
# 1층 매개변수 마련하기
self.params["W1"] = weight_init_std * np.random.randn(input_size, hidden_size) # 정규분포 랜덤에다가 표준편차 0.01을 적용
self.params["b1"] = np.zeros(hidden_size)
# 2층(출력층) 매개변수 마련하기
self.params["W2"] = weight_init_std * np.random.randn(hidden_size, output_size)
self.params['b2'] = np.zeros(output_size)
def predict(self, X):
# 매개변수를 params에서 꺼내옵니다.
W1, W2, b1, b2 = self.params["W1"], self.params["W2"], self.params["b1"], self.params["b2"]
# 1층 계산
z1 = np.dot(x, W1) + b1
a1 = sigmoid(z1)
# 2층 계산
z2 = np.dot(a1, W2) + b2
y = softmax(z2)
return y
def loss(self, x, t):
# 1. predict
y = self.predict(x)
# 2. cee
loss_val = cross_entropy_error(y, t)
return loss_val
# 구현 ㄴㄴ
def accuracy(x, t):
y = self.predict(x)
y = np.argmax(y, axis=1)
t = np.argmax(t, axis=1)
accuracy = np.sum(y==t) / float(x.shape[0])
return accuracy
# 매개변수들의 기울기 배열을 구하는 함수
def numerical_gradient_params(self, x, t):
print("미분 시작")
loss_W = lambda W : self.loss(x, t) # L값 ( 미분 대상 함수 )
# 각 층에서 구해지는 기울기를 저장할 딕셔너리
# 저장하는 이유 : 각 매개변수의 기울기를 저장 해야만 나중에 경사하강법을 수행할 수 있어요
grads = {}
# 1층 매개변수들의 기울기 구하기 (Loss에 대한 W1, b1의 기울기를 grads에 저장)
grads["W1"] = numerical_gradient(loss_W, self.params["W1"])
grads["b1"] = numerical_gradient(loss_W, self.params["b1"])
# 2층 매개변수들의 기울기 구하기 (Loss에 대한 W2, b2의 기울기를 grads에 저장)
grads["W2"] = numerical_gradient(loss_W, self.params["W2"])
grads["b2"] = numerical_gradient(loss_W, self.params["b2"])
print("미분 끝")
return grads코드가 상당히 길어지긴 했습니다. 하지만 지금까지 이야기 한것들을 모두 구현한 것에 불과하기 때문에 순전파 처리를 그대로 코드로 구현한 것입니다.
위 클래스가 사용하는 메소드와 변수들을 정리해 보겠습니다.
변수
- params : 신경망의 매개변수를 보관합니다.
params ['W1']은 1번째 층의 가중치, params ['b1']은 1번째 층의 편향
params ['W2']는 2번째 층의 가중치, params ['b2']도 2번째 층의 편향
- grads : 각 매개변수의 기울기를 보관합니다.
grads['W1']은 1번째 층의 가중치의 기울기, grads ['b1']은 1번째 층의 편향의 기울기
grads ['W2']은 2번째 층의 가중치의 기울기, grads ['b2']은 2번째 층의 편향의 기울기
메소드
- init : 초기화 작업을 수행합니다.
input_size : 입력층의 뉴런 수
hidden_size : 은닉층의 뉴런 수
output_size : 출력층의 뉴런 수
weight_init_std : 생성되는 가중치가 정규분포를 가지기 위한 상숫값
- predict : 예측(추론)을 수행합니다.
x : 이미지 데이터
- loss : 손실 함수의 값을 구합니다.
x : 이미지 데이터
t : 정답 레이블
- accuracy : 정확도를 구합니다. 매개변수는 loss와 같습니다.
- numerical_gradient : 가중치 매개변수의 기울기를 구합니다. 매개변수는 loss와 같습니다.
- gradient : numerical_gradient의 개선판입니다. 오차역전파법을 배우고 나서 구현할 예정입니다. 매개변수는 loss와 같습니다.
# 신경망 생성
input_size = 28*28
hidden_size = 100
output_size = 10
net = TwoLayerNet(input_size=input_size, hidden_size=hidden_size, output_size=output_size)net.params["W1"].shape, net.params["W2"].shape
신경망을 구축하고 나서 신경망을 이해하는데 매개변수 개수를 세는 것만큼 좋은 공부법은 없다고 생각합니다!
총 매개변수의 개수는 몇 개일까요?
- 1층 W : 78,400 1층 b : 100
- 2층 W : 1,000 2층 b : 10
총 79,510개
# 신경망이 predict를 잘 하는지를 보자
x = np.random.rand(100, 784) # 784개의 feature를 가진 100개의 데이터를 랜덤으로 생성 (미니 배치)
y = net.predict(x)x.shape, y.shape
미니 배치 학습 구현하기
실제 MNIST 데이터셋을 이용해 미니배치 학습을 활용해 보겠습니다.
미니 배치 학습이란 훈련 데이터 중 일부를 무작위로 꺼내고(미니배치) 그 미니배치에 대해서 경사법으로 매개변수를 갱신하는 코드를 만들어 보도록 하겠습니다!
MNIST 데이터 로딩 및 전처리
from tensorflow.keras import datasets
mnist = datasets.mnist
(X_train, y_train), (X_test, y_test) = mnist.load_data()X_train.shape, y_train.shape
데이터 전처리
from sklearn.preprocessing import OneHotEncoder
y_train_dummy = OneHotEncoder().fit_transform(y_train.reshape(-1, 1))
y_train_dummy = y_train_dummy.toarray()
y_test_dummy = OneHotEncoder().fit_transform(y_test.reshape(-1, 1))
y_test_dummy = y_test_dummy.toarray()y_train_dummy.shape, y_test_dummy.shape
# feature 전처리
X_train = X_train.reshape(X_train.shape[0], -1)
X_train = X_train / 255.0 # 이미지 정규화 기법. 255.0 으로 나눠주면 모든 픽셀 데이터가 0 ~ 1사이의 값을 갖게 되고, 훈련이 쉽게 된다.
X_test = X_test.reshape(X_test.shape[0], -1)
X_test = X_test / 255.0
X_train.shape, X_test.shape
훈련(학습)
- 미니 배치 선정
- 반복 횟수 설정
- 학습률 선정
# 반복문 돌릴 때 진행 상황을 프로그래스 바로 확인하게 해줌
from tqdm import tqdm_notebook
# 반복 횟수 설정
iter_nums = 10000
# 미니 배치 설정
train_size = X_train.shape[0]
batch_size = 100
# 학습률 설정
learning_rate = 0.1
network = TwoLayerNet(input_size=input_size, hidden_size=hidden_size, output_size=10)for i in tqdm_notebook(range(iter_nums)):
# 미니 배치 인덱스 선정
batch_mask = np.random.choice(train_size, batch_size)
# 미니 배치 만들기
X_batch = X_train[batch_mask]
t_batch = y_train_dummy[batch_mask]
'''
각 배치 마다의 기울기를 계산
network의 numerical_gradient_params에서 하는 일
1. 예측
2. cross_entropy_error를 이용한 Loss 구하기
3. 구해진 Loss값을 이용해 미분을 수행해서 << 각 층의 매개변수 기울기를 저장 >>
'''
grads = network.numerical_gradient_params(X_batch, t_batch)
# 모든 매개변수의 기울기를 업데이트 ( 경사하강법 )
# grads 딕셔너리와 params 딕셔너리의 매개변수 이름이 똑같죠?
for key in grads.keys():
network.params[key] -= learning_rate * grads[key] # 경사하강법 공식
# 갱신된 Loss 확인
loss = network.loss(X_batch, t_batch)
print("Step {} -> Loss : {}".format(i+1, loss))
위 코드에서는 미니배치 크기를 100으로 지정하였습니다.
매번 60,000 개의 훈련 데이터에서 임의로 100개의 데이터를 추려내고, 그 100개의 미니배치를 대상으로 확률적 경사 하강법(SGD)을 수행해 매개변수를 갱신합니다.
경사법에 의한 갱신 횟수(반복 횟수)를 10,000번으로 설정하고, 갱신할 때마다 훈련데이터에 대한 손실 함수를 계산해 그 값을 추가하여 그래프를 그릴 용도로 만들어 놓았습니다.
학습 횟수가 늘어갈수록 손실 함수의 값은 줄어들기 시작하며, 이는 학습이 잘 되고 있다는 것을 뜻합니다.
즉, 신경망의 가중치 매개변수가 데이터에 적응해 나간다고 생각할 수 있습니다.
정리하자면! 데이터를 반복해서 학습함으로써 최적 가중치 매개변수로 서서히 다가서고 있다는 것을 의미합니다.
에폭(epoch)
1 에폭으로 훈련 데이터와 시험 데이터에 대한 정확도를 기록하겠습니다.
여기서 에폭이란 하나의 단위인데요, 1 에폭은 학습에서 훈련 데이터를 모두 소진했을 때의 횟수에 해당합니다.
예를 들어 10,000개의 데이터를 100개의 미니배치로 학습할 경우, 경사법을 100번 진행하면서 반복하면 모든 훈련 데이터를 소진하겠죠? 이 경우에는 100회 훈련했을 때를 1 에폭으로 생각합니다.
테스트 데이터로 평가하기
훈련 데이터를 이용해서 손실 함수의 값이 서서히 내려가는 것이 확인되었습니다.
여기서의 손실 함수의 값이란 정확히는 '훈련 데이터의 미니배치에 대한 손실 함수'의 값이라고 생각할 수 있는데요, 훈련 데이터의 손실 함숫값이 작아지는 것은 신경망이 잘 학습하고 있다는 방증이지만, 다른 데이터셋에도 비슷한 실력을 발휘할지는 아직 확실하지 않습니다.
학습에서는 훈련 데이터 외의 데이터를 올바르게 인식하는지를 확인해야 합니다. 다른 말로 과대적합(overfitting)을 일으키지 않는지를 확인해야 하는데요, 과대적합이 되어버리면 훈련 데이터에 있는 이미지만 잘 구분하고, 그렇지 않은 이미지는 식별할 수 없다는 뜻이 됩니다.
신경망의 학습의 원래 목표는 처음 보는 데이터도 잘 구분할 수 있는 '범용 능력'을 익히는 것입니다.
이 범용 능력을 평가하기 위해서는 훈련 데이터에 포함되지 않는 새로운 데이터인 테스트 데이터를 사용해서 평가해 보아야 합니다. 따라서 학습 도중 정기적으로 훈련 데이터와 시험 데이터를 대상으로 정확도를 기록합니다.
위의 결과에서 알 수 있듯이, 1 에폭마다 (100 개의 미니배치 * 600 회씩 = 60,000 개의 데이터를 훈련용으로 사용할 때마다)의 모든 훈련 데이터와 시험 데이터에 대한 정확도를 계산하고, 그 결과를 기록했습니다.
보통 정확도는 1에폭마다 기록하는데요, for문 안에서 매번 계산하기에는 시간이 오래 걸리기도 하고, 또 그렇게까지 자주 기록할 필요도 없기 때문입니다. 그저 학습 횟수에 대한 정확도 변화 추이만 알 수 있으면 괜찮습니다.
학습이 진행되면서( 에폭이 진행될수록 ) 훈련 데이터와 시험 데이터를 사용하고 평가한 정확도가 모두 좋아지고 있다는 것이 확인됩니다. 또, 두 정확도에는 차이가 거의 없음을 알 수 있습니다. 이번 학습에서는 오버피팅이 일어났다고 보기 힘들다고 생각합니다!
이로써 신경망 학습을 마무리하였습니다!! 다음글에서는 역전파에 대하여 다뤄보도록 하겠습니다!
'Programming > Deep Learning' 카테고리의 다른 글
| [Python/DeepLearning] #10.2. 역전파) 수식을 통한 오차역전파법 이해 (0) | 2024.02.08 |
|---|---|
| [Python/DeepLearning] #10.1. 역전파) 합성함수의 미분과 연쇄법칙 (1) | 2024.02.06 |
| [Python/DeepLearning] #9.2. 수치 미분과 경사하강법(하) (1) | 2024.01.31 |
| [Python/DeepLearning] #9.1. 수치 미분과 경사하강법(상) (0) | 2024.01.29 |
| [Python/DeepLearning] #8. 손실 함수의 종류(Loss Function) (1) | 2024.01.27 |